Web site parsing in command line
What is parsing
Saying parsing, usually mean finding, extracting certain information, analysis data.
Web site parsing can be used to create an online service, as well for penetration testing. For web sites pentester, the skill of parsing sites is basic, i.e. a security auditor (hacker) should be able to do this.
The ability to extract information properly depends on mastery of grep command usage skills. In this article, we will consider the problematic moments of getting the source data, because all sites are different and unusual situations can wait for you, which at the first glance can lead to a dead end.
As an example of parsing sites, here is one single team that receives the titiles of the last ten articles published on Miloserdov.org:
curl -s https://miloserdov.org/ | grep -E -o '<h3 class=ftitle>.*</h3>' | sed 's/<h3 class=ftitle>//' | sed 's/<\/h3>//'

Similarly, you can automate the getting and extracting of any information from any web site.
Features of web site parsing
One of the features of web site parsing is that, as a rule, we work with the source code of the page, i.e. HTML code, not the text that is shown to web site visitors. Therefore when creating a regular expression for grep, you need to build on the source code, not the rendering results. Although there are tools for working with the text resulting from the rendering of the web page - this will also be described below.
In this section, the main focus is on parsing from the Linux command line, since this is the most common (and habitual) work environment for a web application penetration tester. Examples of using different tools from the Linux console will be shown. Nevertheless, the described here techniques can be used on other operating systems (for example, cURL is available in Windows), and also as a library for use in different programming languages.
Retrieving web site content in the Linux command line
The easiest way to get the contents of a web page, or more precisely, its HTML code, is a command of the form:
curl HOST
HOST can be a website address (URL) or an IP address. In fact, curl supports many different protocols - but here we are talking about web sites.
Example:
curl https://miloserdov.org
It is good practice to enclose URLs (web site and page addressed) in single or double quotes, since these addresses can contain special characters that have particular meaning for Bash. Such symbols include the ampersand (&), hash (#), and others.
In order to assign the received data to a variable on the command line, you can use the following construction:
HTMLCode="$(curl https://hackware.ru/)" echo "$HTMLCode"
Here:
- HTMLCode is the name of the variable (note that when you assign (even second time) the variable name is written without the dollar sign ($), and when you use the variable, the dollar sign is always written.
- ="$(COMMAND)" is the construction of a COMMAND without outputting the result to the console; the result of the command is assigned to a variable. Note that neither before nor after the character equals (=) there are no spaces - this is important, otherwise there will be an error.
Also the resulting content of the web page is often piped for processing in other commands:
COMMAND1 | COMMAND2 | COMMAND3
Real examples are given below.
Disabling statistics when using cURL
When you piped the received content (|), you will see that the curl command displays statistics about the speed, time, and amount of data transferred:

To disable statistics output, use the -s option, for example:
curl -s https://miloserdov.org
Automatically follow redirects with cURL
You can instruct cURL to follow the redirects, i.e. open the next page.
For example, if I try to open the site as follows (note HTTP instead of HTTPS):
curl http://hackware.ru/
That I will get:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <html><head> <title>302 Found</title> </head><body> <h1>Found</h1> <p>The document has moved <a href="https://hackware.ru/">here</a>.</p> </body></html>
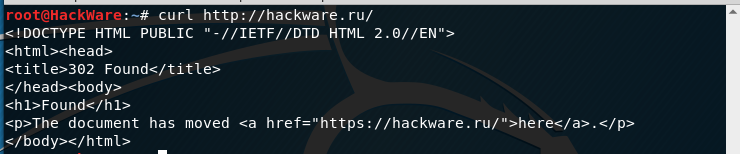
To enable curl to redirect, use the -L option:
curl -L http://hackware.ru/
User Agent spoofing when using cURL
The remote server sees which program is trying to connect to it: it is a web browser, or a web crawler, or something else. By default, cURL passes something like "curl/7.58.0" as User-Agent. Therefore, a server sees that it is not a web browser that connects, but a console utility.
Some websites do not want to show anything to console utilities, for example, if with the usual request:
curl URL
You do not see the contents of the website (you may receive an access denied or ‘bad bot’ message), but when you open your web browser, you can see the page, then we need to apply the -A option, it let us specify any custom user-agent, for example:
curl -A 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36' URL
Receiving web pages with compression using cURL
Sometimes when you use cURL, a warning is displayed:
Warning: Binary output can mess up your terminal. Use "--output -" to tell Warning: curl to output it to your terminal anyway, or consider "--output Warning: <FILE>" to save to a file.
It can be seen, for example, when you try to get a page from kali.org,
curl https://www.kali.org/
The essence of the message is that the curl command will output binary data that can lead to a mess in your terminal. We are offered to use the option "--output -" (note the hyphen after the word output - it means standard output, i.e., displaying binary data in the terminal), or save the output to a file like this: "--output <FILE>".
The reason is that the web page is transmitted using compression, to see the data it is enough to use the --compressed option:
curl --compressed https://www.kali.org/
As a result, the usual HTML code of the requested page will be displayed.
Incorrect encoding when using cURL
Currently, most sites use the encoding UTF-8, with which cURL works fine.
But, for example, when you open some sites:
curl http://z-oleg.com/
Instead of the Cyrillic alphabet, we will see some strange symbols:

The encoding can be converted "on the fly" using the iconv command. But you need to know what encoding is used on the site. To do this, it is usually enough to look at the source code of the web page and find there a line containing the charset word, for example:
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">
This line means that windows-1251 encoding is used.
To convert from the windows-1251 encoding to the UTF-8 encoding using iconv, the command looks like this:
iconv -f windows-1251 -t UTF-8
We will combine it with the curl team:
curl http://z-oleg.com/ | iconv -f windows-1251 -t UTF-8
After that, instead of unknown symbols you will see national letters.
Change the referrer with cURL
Referrer is information about the page with which the user came to this page, i.e. this is the page on which there is a link that the user clicked on to access the current page. Sometimes websites do not show information if the user does not contain the correct referrer information (or they show different information, depending on the type of referrer (search engine, another page of the same site, another site)). You can manipulate the referrer value using the -e option. After that, in quotes, specify the desired value. The real example will be a little lower.
cURL usage on the web pages with basic authentication
Sometimes websites require a username and password to view their content. With the -u option, you can transfer this credential from cURL to the web server as shown below.
curl -u username:password URL
By default, curl uses basic authentication. We can specify other authentication methods using --ntlm | --digest.
cURL and authentication in web forms (GET and POST requests)
Authentication in web forms is the case when we enter login and password into the form on a website. This authentication is used at the entrance to the mail, forums, etc.
Using curl to get a page after HTTP authentication varies very much depending on the particular web site and its engine. Usually, the action scheme is as follows:
1) Use Burp Suite or Wireshark to find out how the data transfer occurs. You need to know: the address of the page to which the data transfer occurs, the transmission method (GET or POST), the transmitted string.
2) When the information is collected, curl is started twice - for the first time for authentication and cookies dumping, the second time - using the received cookies, a page is accessed, which contains the necessary information.
Using a web browser, for us the obtaining and use of cookies is imperceptible. When you go to another web page or even close your browser, the cookies are not erased - they are stored on the computer and used when you go to the site for which they are intended. But curl does not store cookies by default. And so, after successful authentication on the site using curl, if we do not take care of the cookies while we will start curl again, we will not be able to get the data.
To save cookies, use the --cookie-jar option, after which you must specify the file name. For data transfer using the POST method, the --data option is used. Example (the password is changed to incorrect):
curl --cookie-jar cookies.txt http://forum.ru-board.com/misc.cgi --data 'action=dologin&inmembername=f123gh4t6&inpassword=111222333&ref=http%3A%2F%2Fforum.ru-board.com%2Fmisc.cgi%3Faction%3Dlogout'
Then, to get information from a page that only registered users have access to, you need to use the -b option, after which you need to specify the path to the file with previously saved cookies:
curl -b cookies.txt 'http://forum.ru-board.com/topic.cgi?forum=35&topic=80699&start=3040' | iconv -f windows-1251 -t UTF-8
This scheme may not work in some cases, since the web application may require already set cookies when using the first command (there is such behavior on some routers), it may also be necessary to specify the correct referrer, or other data for authentication to be successful.
Extracting information from headers when using cURL
Sometimes you need to extract information from the header, or just find out where the redirection is going.
Headers are some technical information exchanged between a client (web browser or curl program) with a web application (web server). Usually we do not see this information, it includes such data as cookies, redirects, User Agent, encoding, compression, information about the handshake when using HTTPS, HTTP version, etc.
In my practice there is a real example of the need to parse headers. I needed to extract file version number from HTTP response header of Acrylic Wi-Fi Home. The version number is contained in the downloaded file, which has the name like Acrylic_WiFi_Home_v3.3.6569.32648-Setup.exe. In this case, the file name is also absent in the source HTML code, because when you click on the "Download" button, an automatic redirect happens to a third-party site. When preparing a parser for, I ran into the situation that I need to get the file name, and preferably not downloading it.
Example command:
curl -s -I -A 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36' https://www.acrylicwifi.com/AcrylicWifi/UpdateCheckerFree.php?download | grep -i '^location'
The result:
location: https://tarlogiccdn.s3.amazonaws.com/AcrylicWiFi/Home/Acrylic_WiFi_Home_v3.3.6569.32648-Setup.exe
In this command, we already knew the -s (suppress output) and -A options (to specify your custom agent) options.
The new option is -I, which means showing only headers. Therefore, the HTML code will not be displayed, because we do not need it.
In this screenshot, you can see at which moment the information about the new link is sent for the redirection:

An analogous example for the well-known in certain circles Maltego program (once on the site there was no information about the version and I had to write the header parser):
curl -s -v http://www.paterva.com/web7/downloadPaths41.php -d 'fileType=exe&os=Windows' 2>&1 | grep -i 'Location:'
Note that this command did not use the -I option, because it causes an error:
Warning: You can only select one HTTP request method! You asked for both POST Warning: (-d, --data) and HEAD (-I, --head).
The essence of the error is that you can select only one method of the HTTP request, and two are used at once: POST and HEAD.
By the way, the -d option (its alias was mentioned above (--data), when we talked about HTML authentication via forms on websites), transmits data using the POST method, i.e. as if ones clicked on the "Send" button on the web page.
The last command uses the new option -v, which increases the verbality, i.e. the amount of information displayed. But the peculiarity of the -v option is that it does not output additional information (headers, etc.) to standard output (stdout), but to standard error output (stderr). Although in the console it all looks the same, but the grep command does not analyze the headers (as it does in the case with -I option, which prints headers to standard output). You can verify this using the previous command without 2>&1:
curl -s -v http://www.paterva.com/web7/downloadPaths41.php -d 'fileType=exe&os=Windows' | grep -i 'Location:'
The string with Location will never be found, although it is clearly on the screen.
The 2>&1 construct redirects the standard error output to standard output, as a result, nothing changes externally, but now grep can handle these strings.
A more complex command for the previous form handler (try to figure it out yourself):
timeout 10 curl -s -L -v http://www.paterva.com/web7/downloadPaths.php -d 'fileType=exe&client=ce&os=Windows' -e 'www.paterva.com/web7/downloads.php' 2>&1 >/dev/null | grep -E 'Location:'
Parsing web sites on which the text is created using JavaScript
If the content of a web page is generated using JavaScript methods, you can find the required JavaScript file and parse it. However, sometimes the code is too complicated or even obfuscated. In this case, PhantomJS will help.
The peculiarity of PhantomJS is that it is a real command-line tool, i.e. can work on headless machines. Nevertheless, at the same time he can receive the contents of the web page as if you opened it in a normal web browser, including after the operation of JavaScript.
You can get web pages as an image, or just text that is displayed to visitors.
For example, I need to parse the page https://support.microsoft.com/en-us/help/12387/windows-10-update-history and take from it the version number of the last official Windows build. To do this, I create a file called lovems.js:
var webPage = require('webpage');
var page = webPage.create();
page.open('https://support.microsoft.com/en-us/help/12387/windows-10-update-history', function (status) {
console.log('Stripped down page text:\n' + page.plainText);
phantom.exit();
});
To run it, I use PhantomJS:
phantomjs lovems.js
The console will display the contents of the web page in text form, which is shown to users who opened the page in a normal web browser.
To filter the information I need about the latest build:
phantomjs lovems.js | grep -E -o 'OS Build [0-9.]+\)' | head -n 1 | grep -E -o '[0-9.]+'
It will output something like 15063.877.
Parsing in the command line of RSS, XML, JSON and other complex formats
RSS, XML, JSON, etc. are text files in which the data is structured in a certain way. To parse these files, you can, of course, use the Bash tools, but you can greatly simplify your task if you use PHP.
In PHP, there are a number of ready-made classes (functions) that can simplify the task. For example SimpleXML for processing RSS, XML. JSON for JavaScript Object Notation.
If PHP is installed on the system, it is not necessary to use the web server to run the PHP script. This can be done directly from the command line. For example, there is a task from the file at https://hackware.ru/?feed=rss2 extract the names of all the articles. To do this, create a file called parseXML.php with the following contents:
<?php
$t = $argv[1];
$str = new SimpleXMLElement($t);
foreach ($str->channel->item as $new_articles) {
echo $new_articles->title . PHP_EOL . PHP_EOL;
}
You can start the file like this:
php parseXML.php "`curl -s https://hackware.ru/?feed=rss2`"

In this example, to get the file from the web server, use the curl -s https://hackware.ru/?feed=rss2 command, the resulting text file (string) is passed as an argument to the PHP script that processes this data.
By the way, cURL could be used directly from PHP script. Therefore, you can parse in PHP without resorting to the services of Bash. As an example, create a file named parseXML2.php with the following contents:
<?php
$target_url = "https://hackware.ru/?feed=rss2";
$ch = curl_init($target_url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$response_data = curl_exec($ch);
if (curl_errno($ch) > 0) {
echo 'Ошибка curl: ' . curl_error($ch);
}
curl_close($ch);
$str = new SimpleXMLElement($response_data);
foreach ($str->channel->item as $new_articles) {
echo $new_articles->title . PHP_EOL . PHP_EOL;
}
And run it as follows from the command line:
php parseXML2.php
The same file parseXML2.php can be placed in the directory of a web server and opened in your web browser.
Conclusion
Here you can see the situations that you may encounter when parsing websites. The studied material will help to better understand what is happening at the moment when you connect to the website. Because a pentester often uses non-web browsers clients to work with websites: various scanners and tools. Knowledge about referrer, User Agent, cookies, headers, encodings, authentication will help to sort out the problem faster if it arises.
For frequently occurring tasks (collecting email addresses, links), there are already quite a lot of tools - and often you can take a ready solution, and not reinvent the wheel. However, with the help of curl and other command-line utilities you will be able to obtain the data from any site as flexible as possible.
See also: How to get web page content and cookies of .onion sites in Python
Related articles:
- How to use User Agent to attack websites (64.9%)
- How to add reCAPTCHA v3 to protect against parsing and spam (56.1%)
- How to run PHP script without a web server (54.7%)
- Online Kali Linux programs (FREE) (51.4%)
- Searching for admin pages of websites (51.4%)
- Basics of working with a web server for a pentester (RANDOM - 51.4%)