Internet archives: how to retrieve deleted information. How to restore sites from Internet archives
What is Wayback Machine and the Internet Archives
In this article we will consider Web Archives of sites or Internet archives: how to recover removed from sites information, how to download non-existent anymore sites and other examples and use cases.
The principle of operation of all Internet Archives is similar: someone (any user) indicates a page to save. The Internet Archive downloads it, including text, images and design styles, and then saves it. Upon request, the saved page can be viewed from the Internet Archive, and it does not matter if the original page has changed or the site is currently unavailable or completely ceased to exist.
Many Internet Archives store several versions of the same page, taking a snapshot of it at different times. Thanks to this, you can trace the history of changes to the site or web page throughout the years of its existence.
This article will show how to find deleted or changed information, how to use the Internet Archives to restore sites, individual pages or files, as well as some other use cases.
Wayback Machine is the name of one of the popular Internet archive sites. Sometimes the Wayback Machine is used as a synonym for Internet Archive.
What Internet archives exist?
I know about three archives of websites (if you know more, then write them in the comments):
- https://web.archive.org/
- http://archive.md/ (also uses the http://archive.ph/ and http://archive.today/ domains)
- http://web-arhive.ru/
web.archive.org
This web archive service is also known as the Wayback Machine. It has various additional functions, most often used by tools to restore sites and information.
To save the page to the archive, go to https://archive.org/web/ enter the address of the page you are interested in and click the ‘SAVE PAGE’ button.
To view the available saved versions of the web page, go to https://archive.org/web/, enter the address of the page you are interested in or the domain of the website and click ‘BROWSE HISTORY’:

At the very top it says how many total snapshots of the page have been taken, the date of the first and last snapshot.
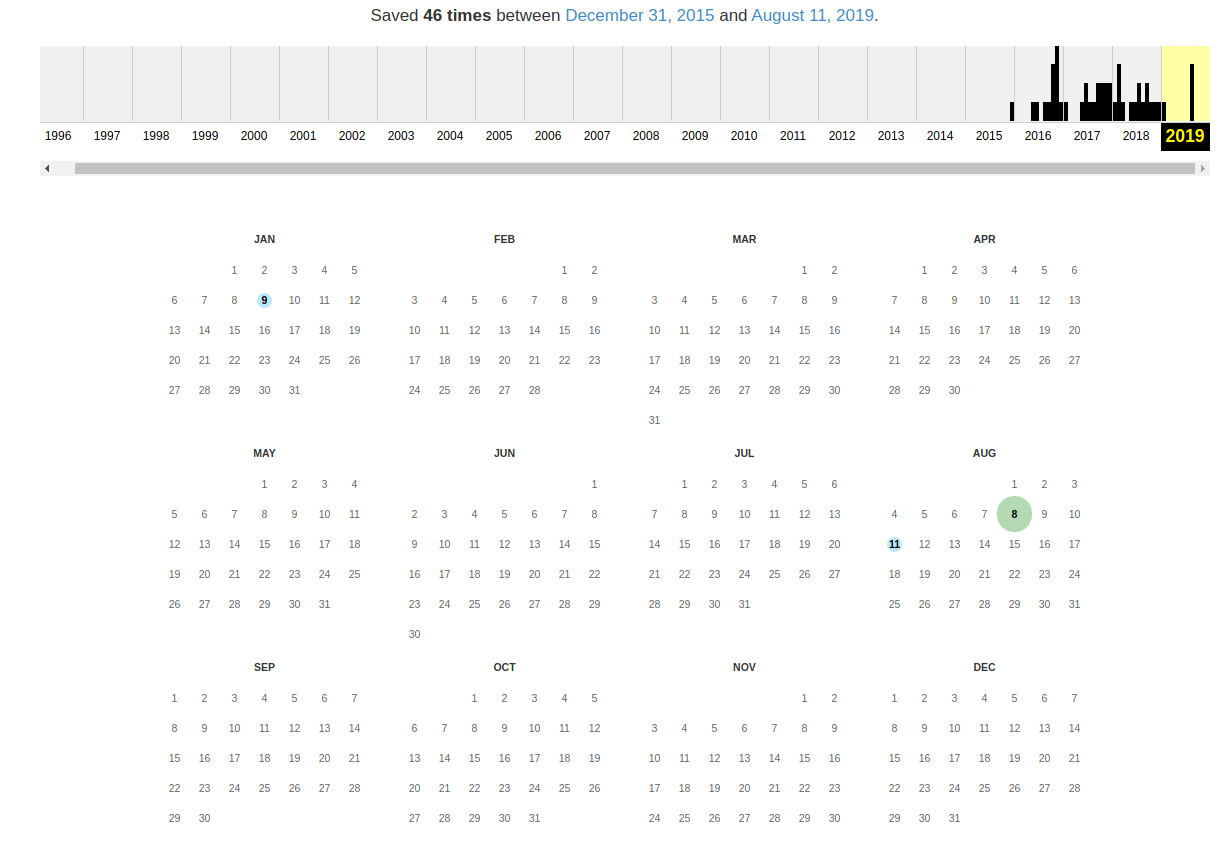
Then there is a time scale on which you can select the year of interest, when choosing a year, the calendar will be updated.
Please note that the calendar does not show the number of changes on the site, but the number of times the page was archived.
Dots on the calendar mean different events, different colors have different meanings about web capture. Blue means that when archiving the page from the web server, a 2nn response code was received (everything is fine); green means that the crawler has received the status 3nn (redirection); orange means that the status is 4nn (error on the client side, for example, the page was not found), and red means that the archiving received a 5nn error (server problems). Most likely, you should be interested in blue and green dots and links.

When you click on the selected time, a link will be opened, for example, http://web.archive.org/web/20160803222240/https://hackware.ru/ and you will be shown how the page looked at that time:

Using these icons, you can go to the next page snapshot, or jump to the desired date:

The best way to see all the files that have been archived for a particular site is to open a link like http://web.archive.org/*/www.yoursite.com/*, for example, http://web.archive.org/*/hackware.ru
In addition to the calendar, the following pages are available:
- Collections. Available as additional features for registered users and by subscription.
- Changes
- Summary
- Site map
Changes
‘Changes’ is a tool that you can use to identify and display changes to the contents of archived URLs.
You can start by selecting two different days of a URL. To do this, click on the appropriate points:
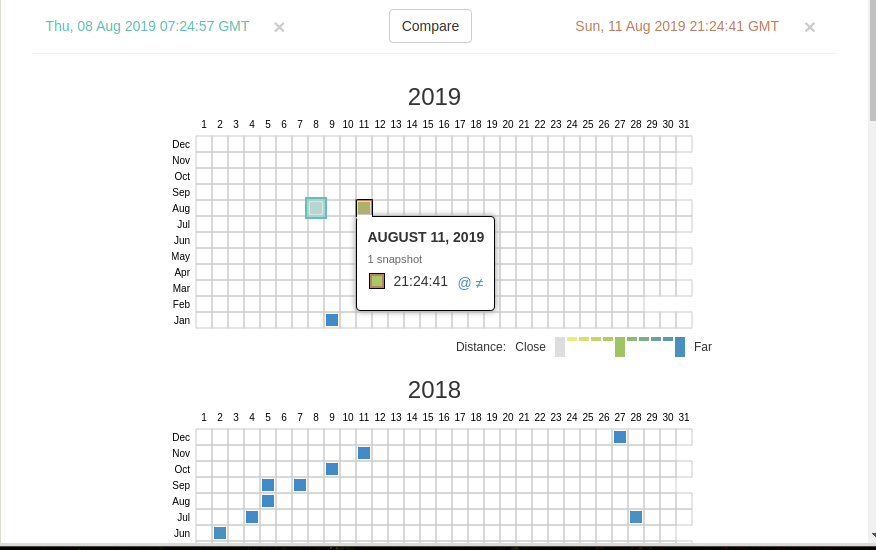
And click the Compare button. As a result, two page options will be shown. Yellow indicates deleted content, and blue indicates added content.
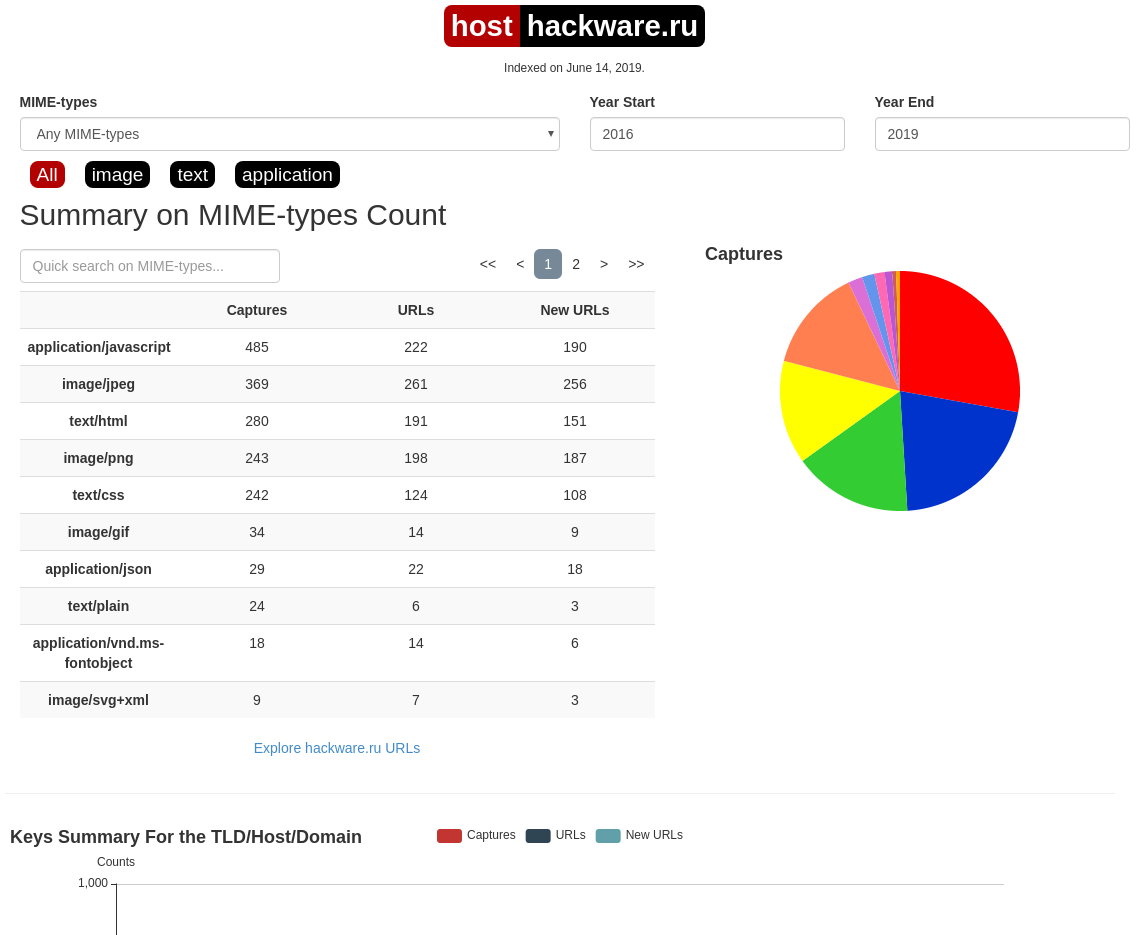
Summary
In this tab, statistics on the number of changes of MIME types.
Site map
As the name implies, a site map diagram is shown here, using which you can go to the archive of the page you are interested in.
Search the Internet archive
If instead of the page address you enter something else, a search will be performed on the archived sites:
Display page for a specific date
In addition to using the calendar to go to the desired date, you can view the page for the desired date using the following link: http://web.archive.org/web/YYYYMMDDHHMMSS/PAGE_ADDRESS/
Please note that in the line YYYYMMDDHHMMSS you can skip any numbers of trailing digits.
If no archive copy is found on the required date, the version for the closest available date will be displayed.
archive.md
Addresses of this Internet Archive:
On the main page, the self-explanatory fields are:
- Archive page that is now online
- Search saved pages

To search the saved pages, you can specify either a specific URL or domains, for example:
- microsoft.com will show pictures from host microsoft.com
- *.microsoft.com will show pictures from the host microsoft.com and all its subdomains (for example, www.microsoft.com)
- http://twitter.com/burgerkingfor will show the archive of the given url (search is case sensitive)
- http://twitter.com/burg* search for archived url starting with http://twitter.com/burg
This service saves the following parts of the page:
- Web page text content
- Images
- Frame content
- Content and images uploaded or generated using Javascript on Web 2.0 sites
- Screenshots of 1024×768 pixels.
The following parts of web pages are not saved:
- Flash and the content it uploads
- Video and Sounds
- RSS and other XML pages are unreliable. Most of them are not saved, or saved as blank pages.
The archived page and all images must be less than 50 megabytes.
For each archived page, a link of the form http://archive.is/XXXXX is created, where XXXXX is the unique identifier of the page. Also, any saved page can be accessed as follows:
- http://archive.is/2013/http://www.google.de/ is the newest snapshot in 2013.
- http://archive.is/201301/http://www.google.de/ - the newest snapshot in January 2013.
- http://archive.is/20130101/http://www.google.de/ - the newest snapshot on the day of January 1, 2013.
The date can be continued further by indicating hours, minutes and seconds:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
To improve readability, the year, month, day, hours, minutes, and seconds can be separated by periods, dashes, or colons:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
It is also possible to refer to all snapshots of the specified URL:
- http://archive.is/http://www.google.de/
All saved domain pages:
- http://archive.is/www.google.de
All saved pages of all subdomains
- http://archive.is/*.google.de
To access the latest version of a page in the archive or the oldest, addresses of the form are supported:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
To access a specific part of a long page, there are two options:
- add a hashtag (#) with a scroll position in the quality of which the number is between 0 (top of the page) and 100 (bottom of the page). For example, http://archive.md/dva4n#95%
- select the text on the pages and get the URL with a hashtag pointing to this section. For example, http://archive.is/FWVL#selection-1493.0-1493.53
Domains support national characters:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Please note that when creating an archive copy of the page, the IP address of the person creating the page snapshot is sent to the archived site. This is done through the X-Forwarded-For header to correctly identify your region and display relevant content.
web-arhive.ru
Archive of Internet (Web archive) is a free service for finding archival copies of sites. Using this service, you can check the appearance and contents of a page on the Internet for a specific date.
At the time of writing, this service, it seems, does not work normally ("Database Exception (# 2002)"). If you have any news on it, then write them in the comments.
Search all Web archives at once
It may happen that the page or file of interest is not in the web archive. In this case, you can try to find the saved page of interest in another Internet Archive. Especially for this, I made a fairly simple service, which for the entered address provides links to page snapshots in the three archives considered.

Service address: https://w-e-b.site/?act=web-arhive
What if the deleted page is not saved in any of the archives?
Internet archives save pages only if some user requested this action – they do not have crawler functions and don’t look for new pages and links. For this reason, it is possible that the page you are interested in may have been deleted before it was saved in any Internet archive.
Nevertheless, you can use the services of search engines that are actively looking for new links and quickly save new pages. To display a page from the Google cache, you need to enter in Google search
cache:URL
For example:
cache:https://hackware.ru/?p=6045
If you enter a similar query into a Google search, the page from the cache will immediately open.
To view the text version, you can use the link of the form:
- http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0
To view the source code of a web page from the Google cache, use the link of the form:
- http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1
For example, a text view:
Source HTML code:
How to completely download a site from a web archive
If you want to recover a deleted site, Wayback Machine Downloader will help you.
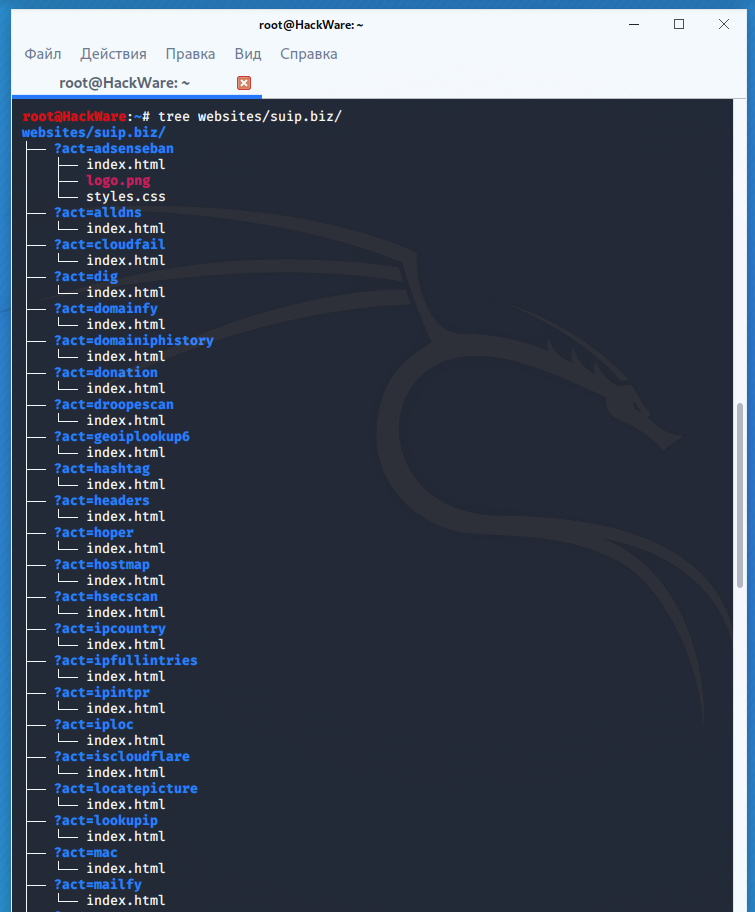
The program will download the latest version of each file present in the Wayback Machine Internet Archive and save it in a folder of the form ./websites/example.com/. It will also recreate the directory structure and automatically create index.html pages so that the downloaded site can be placed on the Apache or Nginx web server without any changes.
To install Wayback Machine Downloader on Kali Linux:
gem install wayback_machine_downloader wayback_machine_downloader --help
To install Wayback Machine Downloader on BlackArch
gem install wayback_machine_downloader sudo mv ~/.gem/ruby/2.6.0/bin/wayback_machine_downloader /usr/local/bin/ wayback_machine_downloader --help
Usage:
wayback_machine_downloader http://example.com
Options
Optional options:
-d, --directory PATH Directory to save the downloaded files into
Default is ./websites/ plus the domain name
-s, --all-timestamps Download all snapshots/timestamps for a given website
-f, --from TIMESTAMP Only files on or after timestamp supplied (ie. 20060716231334)
-t, --to TIMESTAMP Only files on or before timestamp supplied (ie. 20100916231334)
-e, --exact-url Download only the url provied and not the full site
-o, --only ONLY_FILTER Restrict downloading to urls that match this filter
(use // notation for the filter to be treated as a regex)
-x, --exclude EXCLUDE_FILTER Skip downloading of urls that match this filter
(use // notation for the filter to be treated as a regex)
-a, --all Expand downloading to error files (40x and 50x) and redirections (30x)
-c, --concurrency NUMBER Number of multiple files to dowload at a time
Default is one file at a time (ie. 20)
-p, --maximum-snapshot NUMBER Maximum snapshot pages to consider (Default is 100)
Count an average of 150,000 snapshots per page
-l, --list Only list file urls in a JSON format with the archived timestamps, won't download anything
-v, --version Display version
Example of downloading a full copy of the suip.biz website from the Internet archive:
wayback_machine_downloader https://suip.biz
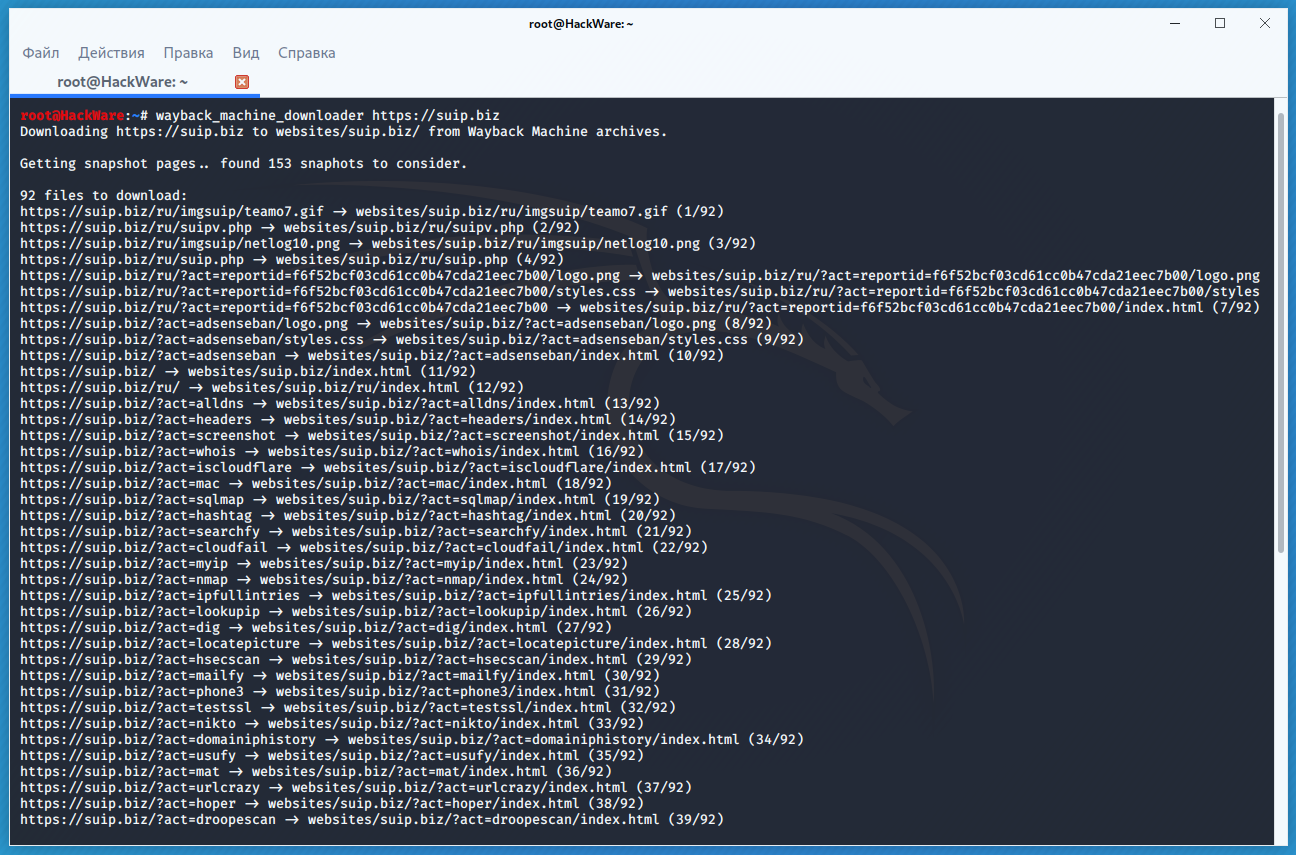
The structure of the downloaded files:
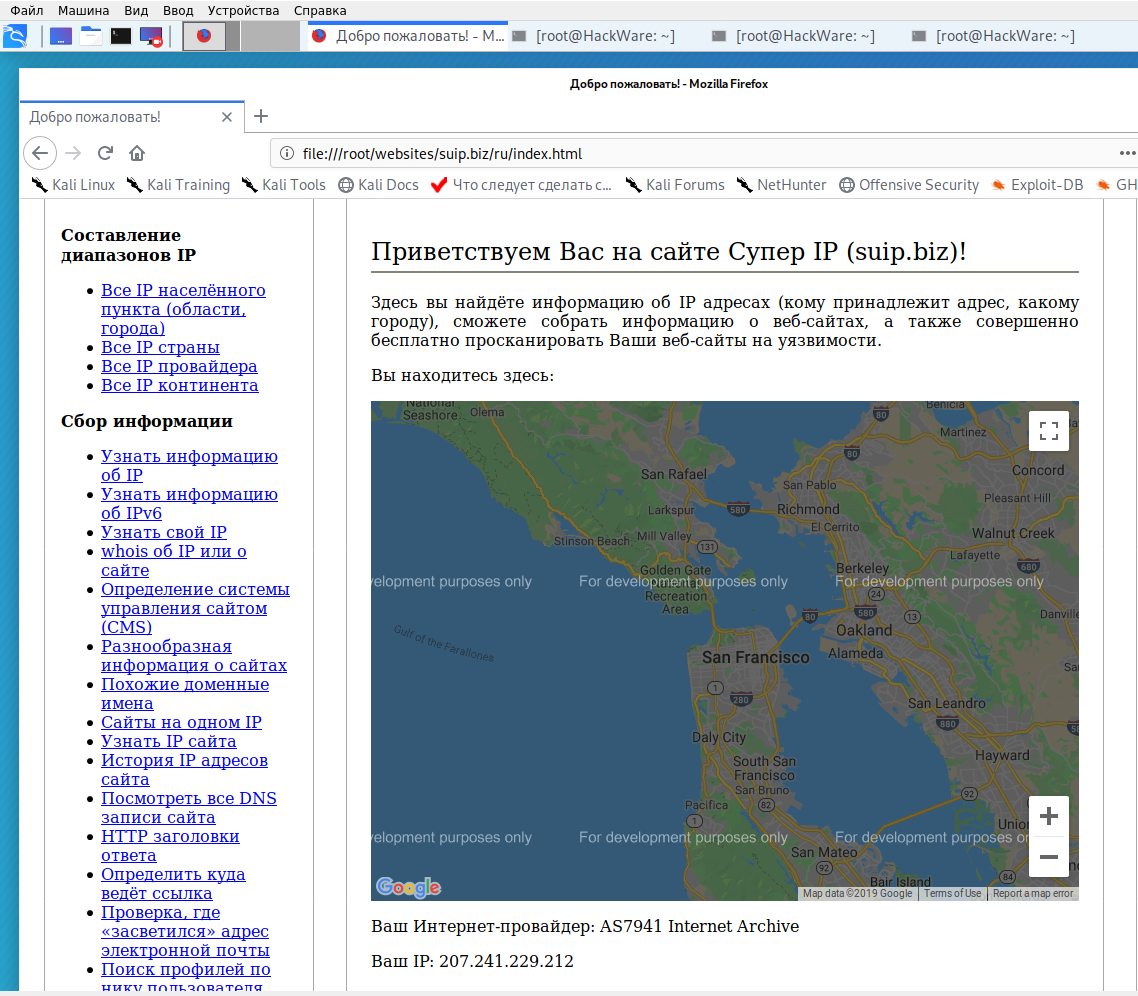
Local copy of the site, pay attention to the Internet service provider:
How to download all page changes from a web archive
If you are not interested in the whole site, but a specific page, but you need to track all the changes on it, then use the Waybackpack program.
To install Waybackpack on Kali Linux
sudo apt install python3-pip sudo pip3 install waybackpack
To install Waybackpack on BlackArch
sudo pacman -S waybackpack
Usage:
waybackpack [-h] [--version] (-d DIR | --list) [--raw] [--root ROOT] [--from-date FROM_DATE] [--to-date TO_DATE] [--user-agent USER_AGENT] [--follow-redirects] [--uniques-only]
[--collapse COLLAPSE] [--ignore-errors] [--quiet]
url
Options:
positional arguments:
url The URL of the resource you want to download.
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
-d DIR, --dir DIR Directory to save the files. Will create this directory if it doesn't already exist.
--list Instead of downloading the files, only print the list of snapshots.
--raw Fetch file in its original state, without any processing by the Wayback Machine or waybackpack.
--root ROOT The root URL from which to serve snapshotted resources. Default: 'https://web.archive.org'
--from-date FROM_DATE
Timestamp-string indicating the earliest snapshot to download. Should take the format YYYYMMDDhhss, though you can omit as many of the trailing digits as you like.
E.g., '201501' is valid.
--to-date TO_DATE Timestamp-string indicating the latest snapshot to download. Should take the format YYYYMMDDhhss, though you can omit as many of the trailing digits as you like.
E.g., '201604' is valid.
--user-agent USER_AGENT
The User-Agent header to send along with your requests to the Wayback Machine. If possible, please include the phrase 'waybackpack' and your email address. That
way, if you're battering their servers, they know who to contact. Default: 'waybackpack'.
--follow-redirects Follow redirects.
--uniques-only Download only the first version of duplicate files.
--collapse COLLAPSE An archive.org `collapse` parameter. Cf.: https://github.com/internetarchive/wayback/blob/master/wayback-cdx-server/README.md#collapsing
--ignore-errors Don't crash on non-HTTP errors e.g., the requests library's ChunkedEncodingError. Instead, log error and continue. Cf.
https://github.com/jsvine/waybackpack/issues/19
--quiet Don't log progress to stderr.
For example, to download all copies of the main page of the suip.biz website, starting from the date (--to-date 2017), these pages should be placed in the folder (-d /home/mial/test), while the program must follow HTTP redirects (--follow-redirects):
waybackpack suip.biz -d ./suip.biz-copy --to-date 2017 --follow-redirects
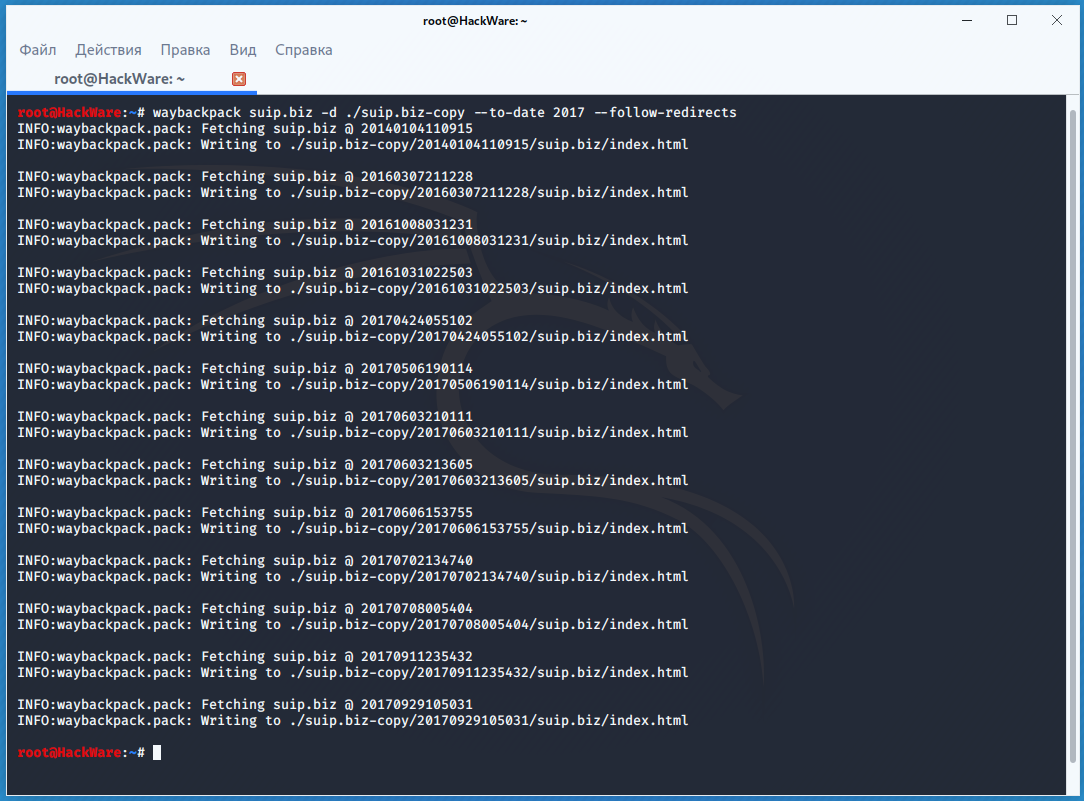
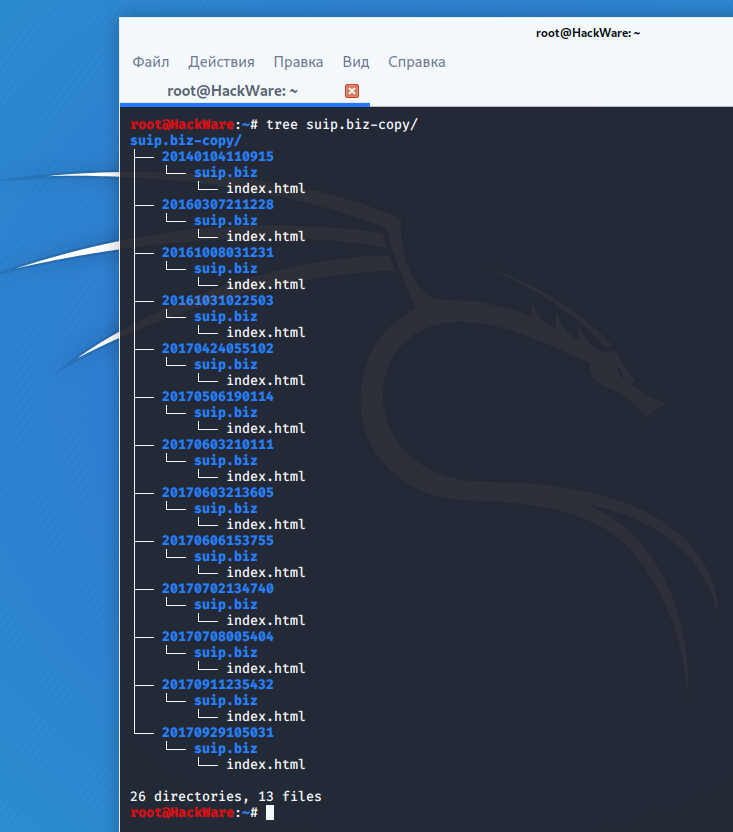
Directory structure:
To display a list of all available copies in the Internet archive (--list) for the specified site (hackware.ru):
waybackpack hackware.ru --list
How to find out all the pages of a site that are saved in the Internet archive
To obtain links that are stored in the Internet Archive, use the waybackurls program.
This program retrieves all the URLs of the specified domain that Wayback Machine knows about. This can be used to quickly map a site.
How to install waybackurls on Kali Linux
Start by installing Go, to do this, go to the article “How to install Go (compiler and tools) on Linux” and select “Manual installation of the latest version of the Go compiler”.
Then type:
go get github.com/tomnomnom/waybackurls waybackurls --help
How to install waybackurls on BlackArch
sudo pacman -S waybackurls
It can work with a list of domains getting it from standard input. In this list, each domain should be written on a separate line.
The program reads domains from standard input, therefore, to start receiving page addresses of one domain, you need to use a command like that:
echo DOMAIN | waybackurls
To get all the URLs of many sites as DOMAINS.txt, you need to specify a file that lists all domains in the format of one domain per line:
cat DOMAINS.txt | waybackurls
Options:
-dates
show date of fetch in the first column
-no-subs
don't include subdomains of the target domain
To get a list of all the pages Wayback Machine knows about for the suip.biz domain:
echo suip.biz | waybackurls
Conclusion
A couple more programs that work with the Internet archive as well:
Related articles:
- badKarma: Advanced Network Reconnaissance Assistant (100%)
- TIDoS-Framework: Web Application Information Gathering and Manual Scanning Platform (100%)
- How to bypass Cloudflare, Incapsula, SUCURI and another WAF (100%)
- How to discover subdomains without brute-force (100%)
- FinalRecon: a simple and fast tool to gather information about web sites, works on Windows (100%)
- How to detect IP cameras (RANDOM - 14.4%)