How to generate dictionaries by any parameters with pydictor
Table of contents
1. Best program for generating dictionaries
3. Dictionaries containing certain characters
4. Dictionary based on custom character sets
5. Prepending and appending strings
6. Permutation and combination of strings
7. Filtering words that match certain conditions
8. Generating dictionaries by mask
9. Custom character sets and masks in pydictor
Best program for generating dictionaries
This tutorial is devoted to the pydictor program. The pydictor utility is a very powerful dictionary generator that probably does everything that can be done with other well-known dictionary generation tools, and has its own unique functionality. The program has many features, but is poorly documented – when preparing this manual, I relied on the translation of Chinese documentation, outdated English documentation, studying the program API, tables with some information from the author, which I was able to decipher only partially, as well as undocumented examples using the program like these:
Usage : --level [level] Example: --level 4 level >= 4 will be work in /funcfg/extend.conf
I hope you appreciate my efforts ))
As the author of the program himself says (or maybe it's just some kind of Chinese wisdom): “Destination is just a point of departure. It's your show time”. So let's get started with pydictor already.
Pydictor instruction
The main principle of pydictor is as follows: there are dictionary generation methods with which word lists are created. Simultaneously with the choice of the generation method, you can select the function for modifying the dictionary or filtering so that the generated dictionaries meet certain conditions.
The dictionary generation methods are as follows:
| Type | Dictionary generation method | Identifier | Description | Supported functions (explanation below) |
|---|---|---|---|---|
| Core | base | C1 | Dictionary based on selected groups of characters | F1 F2 F3 F4 |
| Core | char | C2 | Dictionary based on a custom character set | F1 F2 F3 F4 |
| Core | chunk | C3 | Dictionary based on permutation and combination | ALL |
| Core | conf | C4 | Dictionary based on rules from the specified configuration file | ALL |
| Core | pattern | C5 | Quickly generated dictionary based on a template | F2 F3 F4 |
| Core | extend | C6 | Extended rule-based dictionary | ALL |
| Core | sedb | C7 | Dictionary based on social engineering | ALL |
| Tool | combiner | T1 | Tool for combining files in a specified directory | |
| Tool | comparer | T2 | A tool for comparing and finding differences in file contents | ALL |
| Tool | counter | T3 | Word frequency counting tool | ALL |
| Tool | handler | T4 | Input file processing tool | ALL |
| Tool | uniqbiner | T5 | Tool for combining and unique files in a directory | ALL |
| Tool | uniqifer | T6 | Input file uniqueization tool | ALL |
| Tool | hybrider | T7 | A tool to combine words from multiple dictionaries | F1 F2 F3 F4 |
| Plugin | birthday | P1 | A list of words by birthday keywords is built based on the entered date and time | ALL |
| Plugin | ftp | P2 | Generating FTP passwords by keywords | ALL |
| Plugin | pid4 | P3 | Dictionary with the last 4 characters of the (Chinese) ID card | ALL |
| Plugin | pid6 | P4 | Dictionary with the last 6 characters of the (Chinese) ID card | ALL |
| Plugin | pid8 | P5 | Dictionary with the last 8 characters of the (Chinese) ID card | ALL |
| Plugin | scratch | P6 | Word list based on keywords from web pages | ALL |
The functions are as follows:
| Function | Code | Description |
|---|---|---|
| len | F1 | Length range |
| head | F2 | Add prefix (line at the beginning of a word) |
| tail | F3 | Add suffix (line to end of word) |
| encode | F4 | Encode or hash all generated words |
| occur | F5 | Filter by the maximum frequency of occurrence of letters, numbers, special characters |
| types | F6 | Filter by the minimum frequency of occurrence of letters, numbers, special characters |
| regex | F7 | Regular expression filter |
| level | F8 | Sets the level of the dictionary rules |
| leet | F9 | Enables 1337 mode |
| repeat | F10 | Filter by the number of consecutive letters, numbers, special characters |
Only one generation method can be selected in one command. As for the functions, you may select: not use them at all, use one or several at once – depending on your needs.
You can see the pydictor options on this page: https://en.kali.tools/?p=1320
It is easy to get confused in them, since the commands for choosing the generation method and the filtering function are mixed together. Some more options start with one hyphen, some with two – I didn't see any logic why this was done like that. Taking these inconveniences, let's look at examples of generating dictionaries with pydictor.
Dictionaries containing certain characters
Let's start by generating word lists of specific characters and word lengths. This is a bit like generating dictionaries based on masks (Mask attack), although different from it.
The -base option specifies the character sets that the generated words should include, you can choose from:
d digital [0 - 9]
L lowercase letters [a - z]
c capital letters [A - Z]
dL Mix d and L [0-9 a-z]
dc Mix d and c [0-9 A-Z]
Lc Mix L and c [a-z A-Z]
dLc Mix d, L and dL [0-9 a-z A-Z]
The “--len MINIMUM MAXIMUM” option specifies the length range. The default values are: min=0 and max=4.
For example, the following command will generate a list of words consisting of small letters (-base L), two to three characters long (--len 2 3):
python3 pydictor.py -base L --len 2 3
Pay attention to the lines:
[+] A total of :18252 lines [+] Store in :/home/mial/bin/pydictor/results/base_120010.txt [+] Cost :0.0663 seconds
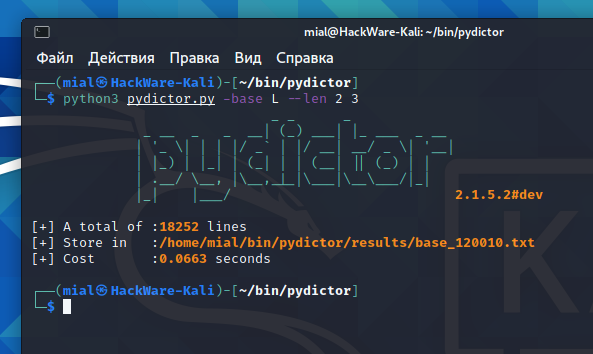
- A total of :18252 lines – means that a total of 18252 words were generated.
- Store in :/home/mial/bin/pydictor/results/base_120010.txt – means that the dictionary was saved in the base_120010.txt file at the specified path
- Cost :0.0663 seconds – shows the time taken to generate the dictionary
Let's look at the beginning and end of the dictionary:
head results/base_120010.txt tail results/base_120010.txt

With the -o, --output option, you can specify the path and file name where the dictionary should be saved:
python3 pydictor.py -base L --len 2 3 --output ~/dic.txt
To generate words from 1 to 3 characters long (--len 1 3) from numbers, uppercase and lowercase letters (-base dLc) and save them to the specified file (-o /awesome/pwd):
python3 pydictor.py -base dLc --len 1 3 -o /awesome/pwd
Dictionary based on custom character sets
Custom character sets are specified with the -char option. Remember to put the character string in quotation marks if there are spaces or other special characters in the set.
The following command will create words of length 1 to 3, consisting of the characters “asdf123._@ ”:
python3 pydictor.py -char 'asdf123._@ ' --len 1 3
Prepending and appending strings
There are two options for adding strings:
--head PREFIX Adds a line to the beginning of each word --tail SUFFIX Adds a line to the end of each word
In similar programs, for example, Maskprocessor and crunch, there is no need for such options – you just need to write literal characters in the mask. But pydictor is a more flexible program that can generate dictionaries, including not based on masks, but, for example, by combining words from different dictionaries or from data about the “victim”. Since masks are not used in these examples, the --head and --tail options come to the rescue.
The following command will create a list of words containing only numbers (-base d), four characters long (--len 4 4), the word Pa5sw0rd (--head Pa5sw0rd) will be added before each line and the dictionary will be saved to file D:\exists\or\not\dict.txt (--output D:\exists\or\not\dict.txt):
python3 pydictor.py -base d --len 4 4 --head Pa5sw0rd --output D:\exists\or\not\dict.txt
An example of a command in which words from 1 to 3 characters long (--len 1 3) will be composed from a custom character set (-char 'asdf123._@ '), the line “@site.com” line will be added to the end of each word (--tail @site.com):
python3 pydictor.py -char 'asdf123._@ ' --len 1 3 --tail @site.com
Permutation and combination of strings
With the -chunk option, you can perform actions similar to Combinator attack. But a Combinator attack in Hashcat can work with two or three dictionaries. And in pydictor, you can concatenate and combine any number of string fragments. For a Combinator attack in Hashcat, see the article Advanced wordlist generating techniques.
To make it clear what exactly is happening, let's look at the output of the following command:
python3 pydictor.py -chunk Строка1 Строка2 Строка3 Строка4
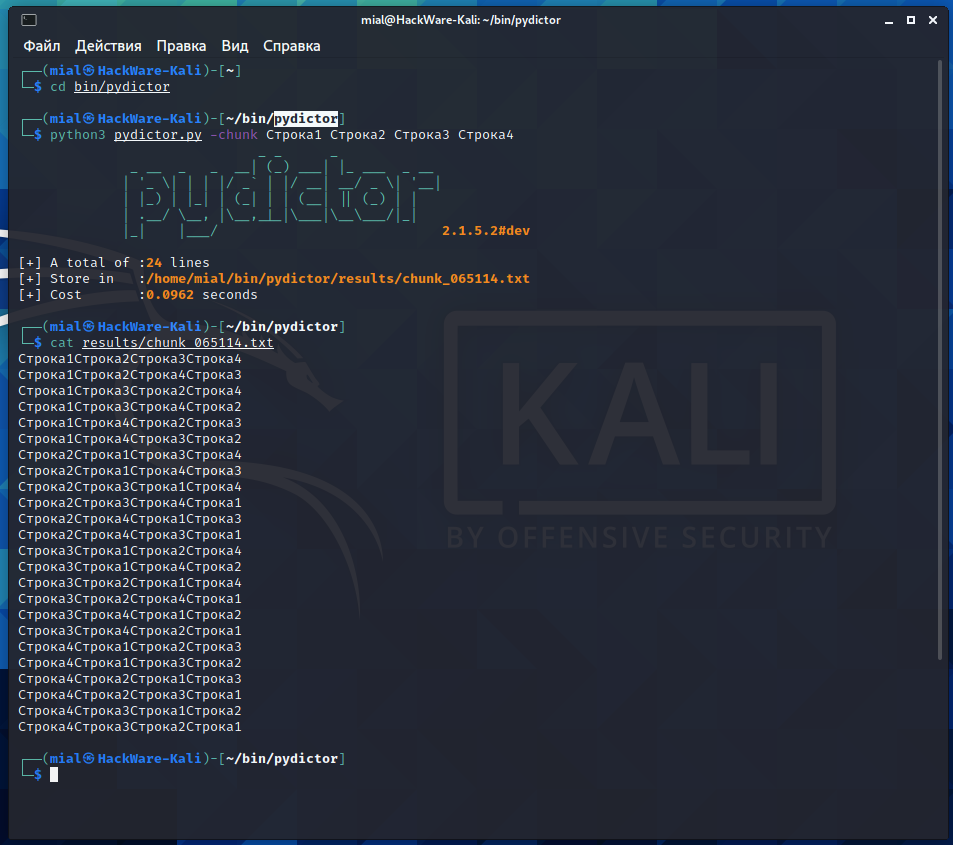
That is, the arguments to the -chunk option are combined in all possible combinations, each line being used once.
I think the essence is clear, in the following command, words are generated from six fragments of different lengths, to which lines are then added at the beginning and end:
python3 pydictor.py -chunk abc 123 '!@#' @ . _ ' ' --head a --tail @pass
Filtering words that match certain conditions
In pydictor, you can filter or create lists of words that match the conditions:
- minimum or maximum number of characters of a certain group (number, letter, special)
- minimum and maximum number of consecutive repetitions of symbols of a certain group (number, letter, special)
To do this, pydictor has the following options:
--occur LETTER NUMBER SPECIAL
Filter by the maximum frequency of occurrence of letters, numbers, special characters. Default: LETTER "<=99" NUMBER "<=99" SPECIAL "<=99"
--types LETTER NUMBER SPECIAL
Filter by the minimum frequency of occurrence of letters, numbers, special characters. Default: LETTER ">=0" NUMBER ">=0" SPECIAL ">=0"
--repeat LETTER NUMBER SPECIAL
Filter by the number of consecutive letters, numbers, special characters. Default: LETTER ">=0" NUMBER ">=0" SPECIAL ">=0"
The options discussed can also be used with dictionary processing tools (they will be discussed in the next part) when combining dictionaries, cleaning, and other actions.
These options are a bit like Rule-based attack, but they are easier to apply (although a full Rule-based attack is more flexible).
Comparison operators can be used with these options:
- >= means greater than or equal
- > means more
- == means equal
- <= means less or equal
- < means less
The section “How to create dictionaries that comply with specific password strength policies (using Rule-based attack)” shows the principles of generating dictionaries that meet certain criteria. In short, the essence is as follows:
- first, a wordlist is created that includes all possible options
- then, using Rule-based attack, only suitable password candidates are filtered out
- in real life, no one does this, since the size of the dictionary is too large
Therefore, we will consider an example of filtering words that meet certain conditions from a ready-made dictionary.
Download and unpack the dictionary:
wget -U 'Not a foe' https://kali.tools/files/passwords/leaked_passwords/rockyou.txt.bz2 bunzip2 rockyou.txt.bz2
If you are on Kali Linux, then the dictionary is already there, just unpack it:
cat /usr/share/wordlists/rockyou.txt.gz | gunzip > ~/rockyou.txt
Let's clear the dictionary of unreadable characters:
iconv -f utf-8 -t utf-8 -c ~/rockyou.txt > ~/rockyou_clean.txt
For details on the problem solved by the previous command, see the article How to find and remove non-UTF-8 characters from a text file.
The following command will take ~/rockyou_clean.txt as the source file, and remove all duplicate words (-tool uniqifer ~/rockyou_clean.txt), then it will filter the list of words, with each word having three or more letters, more than two digits and zero special characters (--occur ">=3" ">2" "==0"), the result should be saved to the specified file (--output ~/uniq.txt):
python3 pydictor.py -tool uniqifer ~/rockyou_clean.txt --occur ">=3" ">2" "==0" --output ~/uniq.txt
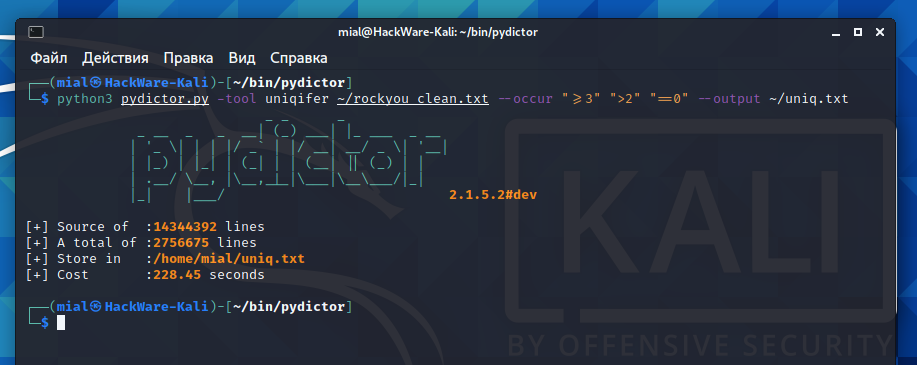
The following command will only save words with 8 or fewer letters, 4 or fewer numbers, and 0 special characters:
python3 pydictor.py -tool uniqifer ~/rockyou_clean.txt --types "<=8" "<=4" "==0" -o ~/uniq.txt
This command will only save words where letters are repeated 3 or less times and numbers are repeated 3 or more times:
python3 pydictor.py -tool uniqifer ~/rockyou_clean.txt --repeat "<=3" ">=3" "==0" -o ~/uniq.txt
Generating dictionaries by mask
There are several options at once to emulate a Mask Attack:
- --pattern
- --regex (does not work with all dictionary generation methods)
- --conf
They are all poorly documented, and their work differs from the intuitively expected behavior.
The --conf option allows you to use the file in which the template of words for generation is written. You might think that the --pattern option allows you to specify the same pattern as in the --conf file. But this is not the case! Their format is different!!!
With the --conf option, you can specify the path to the file where the template is written, and you can also specify the template string (in fact, the mask), according to which the dictionary will be generated.
One symbol represents a five-element construct:
- prefix,
- character set,
- length range,
- encoding (hashing),
- suffix.
Of these, you can omit the prefix and suffix, and the other three are required.
Suppose we want to generate a list of words consisting of three digits (mask ?d?d?d), then the command is as follows (note: the site engine cannot master and correctly display the < none > lines, therefore some commands are shown in pictures):
![]()
In it:
- [0-9] – range of characters
- {3,3} – the number of characters from this range
- <none> – do not use encoding for this character
Now, let's say we want passwords in which a number comes first, then a small letter, then two numbers (mask ?d?l?d?d), then the construction is as follows:
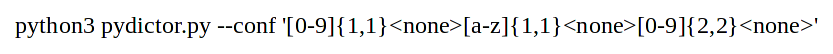
Sounds complicated? Don't be in a hurry to get upset. When you realize how much flexibility this syntax has, you will appreciate it.
If you need to specify literal characters, then they do not require special syntax, for example, the command:
![]()
will create the following list:
0Password00 0Password01 0Password02 0Password03 0Password04 0Password05 0Password06 0Password07 0Password08 0Password09 0Password10 0Password11 …………………. …………………. ………………….
In the command shown, the literal string becomes the prefix or suffix of one of the elements.
Custom character sets and masks in pydictor
In the previous examples, we used ranges such as [0-9] (all digits) and [a-z] (all small letters). But you can specify any ranges, for example:
- [1-5] – numbers from 1 to 5
- [a-g] – small letters from a to g
- [a,d,q,r,s] – only letters a, d, q, r, s
- [a-g,I,M-O,1-4] – a range of lowercase letters from a to g, a capital letter I, and a range of uppercase letters from M to O, as well as numbers from 1 to 4.
Take a look at the following example:
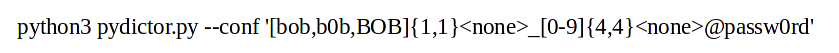
In it, the range includes not individual characters, but the strings bob, b0b and BOB. That is, the first part of the generated words will include one of these lines, then there will be four digits, and at the end there will be the string “@passw0rd”.
End of the first part
We covered the basics of using pydictor, and the instruction turned out to be quite voluminous, so we will get acquainted with other features and tools of this program in the next part.
Related articles:
- Advanced wordlist generating techniques (100%)
- How to create dictionaries that comply with specific password strength policies (using Rule-based attack) (66.2%)
- How to use .hcmask files in Hashcat for the most flexible character replacement (63.1%)
- How to generate candidate passwords that match password strength policies (filtering words with grep) (61.4%)
- Comprehensive Guide to John the Ripper. Part 5: Rule-based attack (59%)
- How to hack Wi-Fi using Reaver (RANDOM - 0.8%)