How to see locked HTML code, how to bypass social content lockers and other website info gathering countermeasures
Is it possible to protect the HTML code of a web page?
The source code of the web page cannot be protected from viewing. It is a fact. But you can make code analyzing task more difficult. Completely inefficient methods include locking the right mouse button. The more effective means include obfuscation of the code. Especially if the code is not present in the source text of the page, but is loaded from different files using JavaScript and if at different stages (JavaScript and HTML itself) are also obfuscated. In this case, everything becomes much more difficult. But such cases are quite rare – more often found on the websites of very large companies. We will consider simpler options.
How to view the source HTML code of a web page if the right mouse button and CTRL+u are locked
If the right mouse button does not work, then just press CTRL+u. I came across a site where CTRL+u also refused to work:
CTRL+u can be disabled using JavaScript. That is, the first option is obvious – with disabled JavaScript the source code will not be “locked”.
Another option is to find the option “Show source code” in the browser menu. In Firefox, this option is there, but personally it always takes me a lot of time to find it))) In Chrome, I can't find this option at all in the browser menu, so remember the line
view-source:
If this line is added before any address of the site and all this is inserted into the tab of a web browser, the source code of this page will be opened.
For example, I want to see the HTML of the https://suip.biz/?act=view-source page, then I insert the line view-source:https://suip.biz/?act=view-source in the tab web browser and get the source code in it.
By the way, if it’s hard for you to remember the view-source, then here’s the appropriate service: https://suip.biz/?act=view-source (don’t laugh at its “complexity” - none can remember everything in life, and sometimes it’s really easier to open such page and use it to get the string you need to view the source code).
By the way about disabling JavaScript – it is not necessary to climb into the ‘deep’ browser settings and look for where this option is. You even do not need to disable JavaScript, it is enough to pause the execution of scripts for a specific page.
To do this, press F12, then in the developer tools, go to the Sources tab and click there F8:
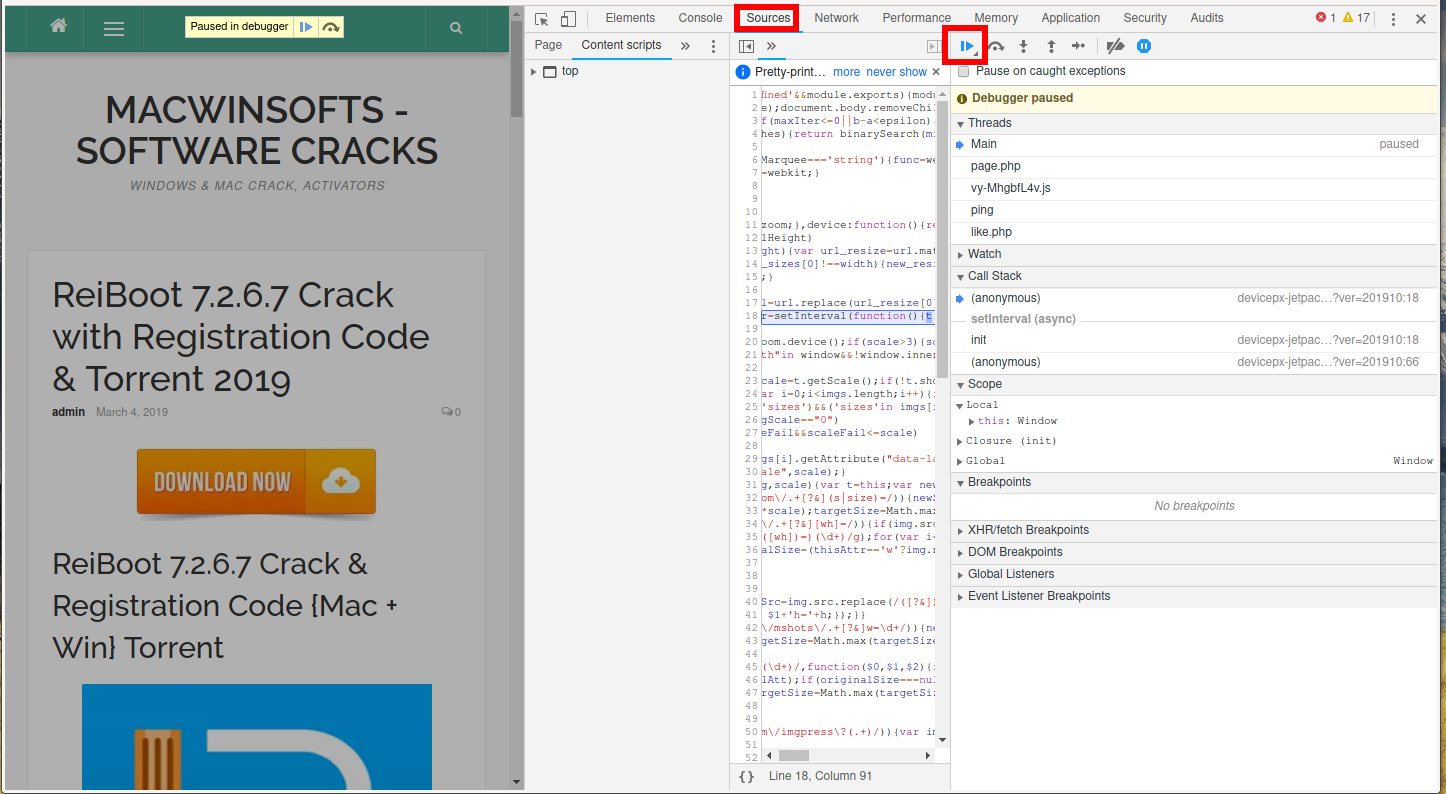
Now the CTRL+u key combination will work on the site page, as if it has never been disabled.
Bypassing social content lockers
The social content lockers looks like this:
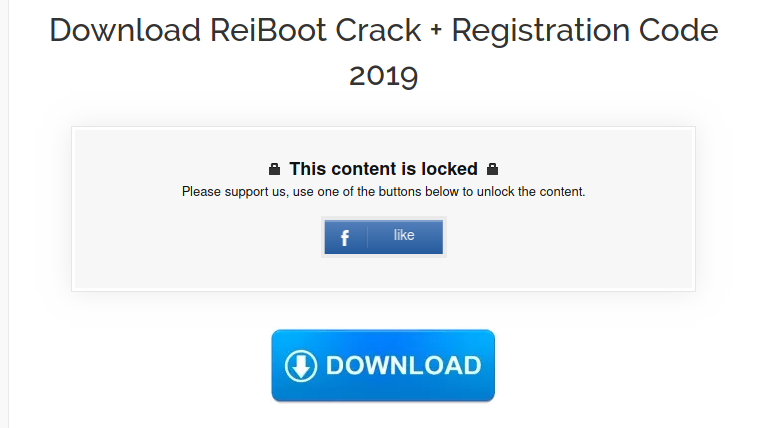
The point is the following, to view the content, you need to ‘like’ this article on the social network.
“Under the hood” there is everything (usually) like this: “hidden” text is already present in the HTML page, but is hidden with the style property style="display: none;". Therefore, it is enough:
- open the HTML page protected by social content lockers
- find all occurrences style="display: none;" - usually they are not very many.
An example of “hacking” a social content lockers:
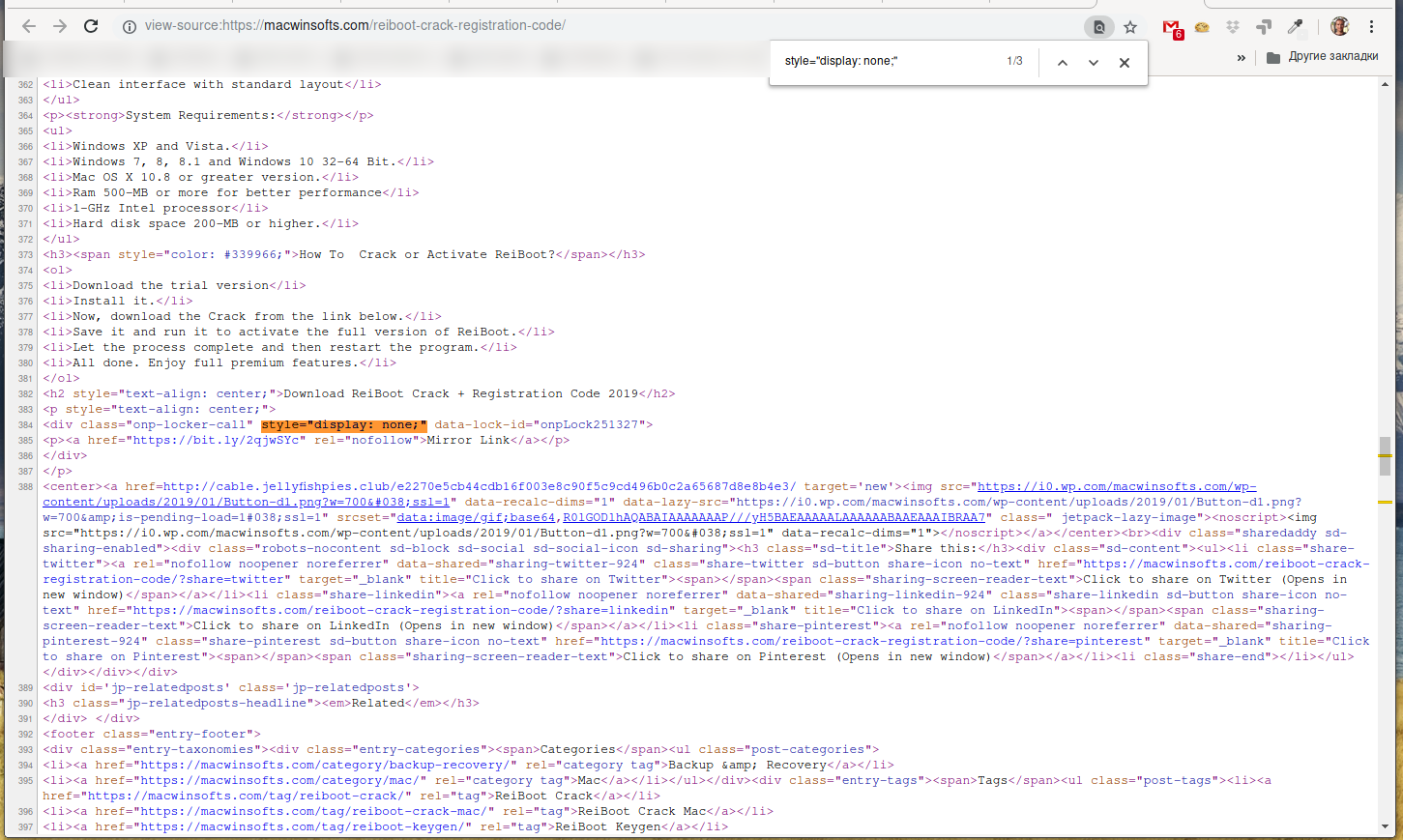
Hidden text:
<p style="text-align: center;"> <div class="onp-locker-call" style="display: none;" data-lock-id="onpLock251327"> <p><a href="https://bit.ly/2qjwSYc" rel="nofollow">Mirror Link</a></p> </div> </p>
But every time it’s not very convenient to climb into the source code, and I … made an online service that itself retrieves data hidden by social blockers for you, its address: https://suip.biz/?act=social-locker-cracker
It is able to bypass four social content lockers and got a “heuristic” analysis – it turns on if no result found, then it displays the contents of all blocks with style="display: none;".
By the way, if you come across pages that this service cannot bypass – just write a link to the problem page in the comments – I will add the appropriate ‘handler’.
The site that I show in the screenshots seems to spread counterfeit software. I looked at the links with the help of the cracker of social content lockers – it turned out that all the hidden links are absolutely non-bonded: they lead to the demo version of the programs or to the official website. In some articles there are no links at all. I was interested in such “marketing” and I decided to search other sites of the same author.
Search for fake pirate sites
On the “Checking if the site uses CloudFlare” service, we check:
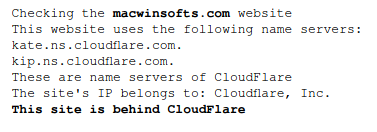
This site is behind CloudFlare – Ha ha, classic!
We look at the history of the IP domain on securitytrails: https://securitytrails.com/domain/macwinsofts.com/history/a
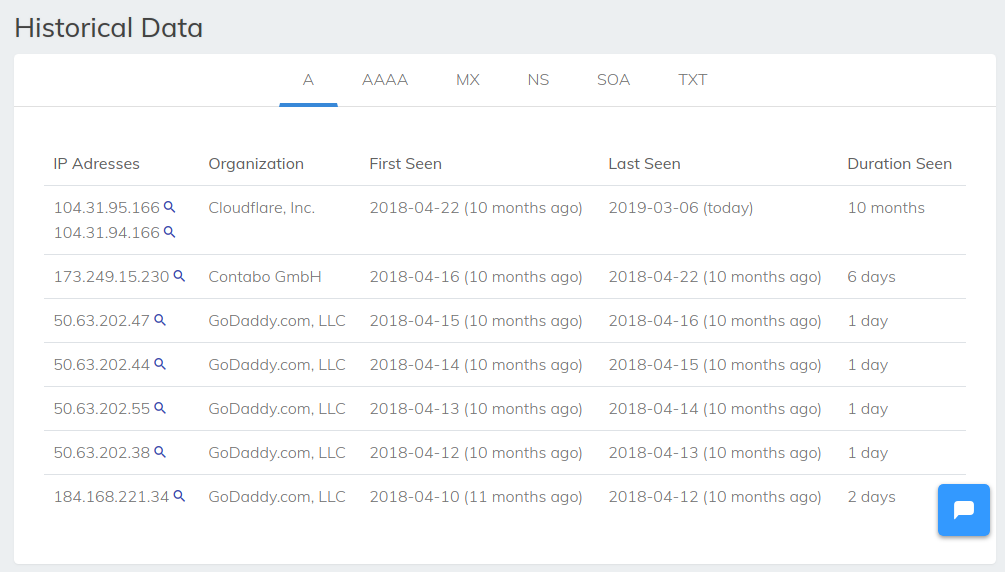
We see there:
- Cloudflare, Inc. - these are today's IP addresses
- GoDaddy.com, LLC - auction, domain parking and the like
- Contabo GmbH - quite possible real hosting where this site is located
So, it is likely that the IP of this site is 173.249.15.230. At present, there is no information on the associated sites on the securitytrails for this IP.
Therefore, we go to the “List of sites on one IP” service, enter 173.249.15.230 as source data and get there:

List:
- haxsofts.com
- crackways.com
- crackmafia.org
All sites have a similar modus operandi, everywhere there is a social content locker, everywhere instead of a pirate links there are links to the demo version, links to official sites, or there is simply nothing under the locked content.
Site IP Verification with cURL
For IP verification, I usually use the following command:
curl -v 173.249.15.230 -H 'Host: SITE_ADDRESS'
For example:
curl -v 173.249.15.230 -H 'Host: macwinsofts.com'
Or so, if you need to check the site on the HTTPS protocol:
curl -v https://173.249.15.230 -H 'Host: macwinsofts.com'
But server 173.249.15.230 is configured so that absolutely any host, even if you write “dfkgjdfgdfgfd” there, it redirects to the address with HTTPS, that is, to “https://dfkgjdfgdfgfd”. And the server itself does not accept requests via HTTPS at all – the web server is not configured to process them and port 443 is not even open.
In principle, it can be proved indirectly that this server is configured to process the macwinsofts.com host, for example, this request almost instantly causes an error 503:
curl -v 173.249.15.230/wp-content/uploads/2018/10/ReiBoot-Crack-Mw.png -H 'Host: fake.com'
But this request, although it will also cause an error 503, but will force the server ‘to think’ for a long time:
curl -v 173.249.15.230/wp-content/uploads/2018/10/ReiBoot-Crack-Mw.png -H 'Host: macwinsofts.com'
Apparently, there, due to the peculiarities of the settings, endless redirects occur and in the end the connection is reset on timeout.
This method allows including brute-force files and folders:
curl -v 173.249.15.230/.htaccess -H 'Host: macwinsofts.com'

And quite an interesting result is such a query:
curl -v 173.249.15.230/wp-content/uploads/2018/10/ReiBoot-Crack-Mw.png -H 'Host: ya.com'
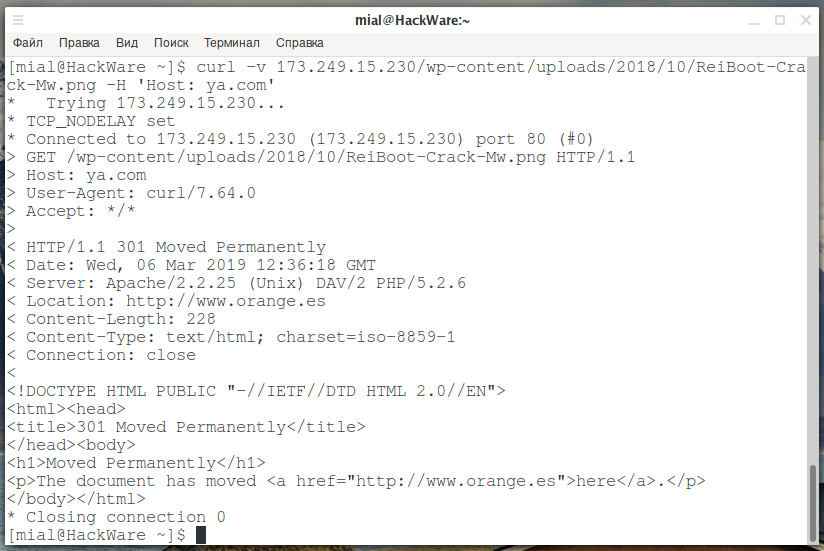
Conclusion
What is the meaning of these sites? Some of them have .exe files for download – perhaps viruses or some dubious monetization. Although I checked on virustotal – like, the file is not malicious. Those sites that do not have executable files for download, apparently waiting for the growth of traffic, to then begin to distribute this executable file.
Perhaps the owner expects an increase traffic to enable monetization or to spread viruses.
Related articles:
- Utilities for information gathering, OSINT and network analysis in Windows and Linux (56.3%)
- Revealing the perimeter (CASE) (56.3%)
- Open source research with OSRFramework (search by mail, nickname, domain) (55.5%)
- How to install ꓘamerka (kamerka) (55.5%)
- How to save all information from Facebook profiles (55.5%)
- lulzbuster: a tool for quick enumeration of hidden files and folders on sites (RANDOM - 1.8%)
can you unlock this file man https://premiumleakshub.com/high-ticket/executive-deangelo-cpa-level-2-worth-497
Social content locker hides only this:
And web form for registration. Nothing else.
BTW, be careful. This shit is sort of scam!
Hidden HTML:
<div class="onp-locker-call" style="display: none;" data-lock-id="onpLock689078"><p> <style>.ihc_locker_4 .lock_content{color:#000}.ihc-login-template-5 .impu-form-line-fr input[type=text],.ihc-login-template-5 .impu-form-line-fr input[type=password]{color:#fff} </style> <div class="ihc-locker-wrap"> <div style='' class='ihc_locker_4'> <div class='lk_wrapper'> </div> <div class='lk_left_side'> </div> <div class='lock_content'> <p><h2>You need to be subscribed!</h2> Oops! Looks like you have yet to subscribe to our awesome site's VIP/Executive Membership! What are you waiting for? Login or Register now!</p> <div class='lock_buttons'><div class="ihc-login-form-wrap ihc-login-template-5"> <form action="" method="post" id="ihc_login_form"> <input type="hidden" name="ihcaction" value="login" /> <input type="hidden" name="locker" value="1" /> <div class="impu-form-line-fr"> <span class="impu-form-label-fr impu-form-label-username">Username:</span> <input type="text" value="" id="iump_login_username" name="log" /></div> <div class="impu-form-line-fr"><span class="impu-form-label-fr impu-form-label-pass">Password:</span> <input type="password" value="" id="iump_login_password" name="pwd" /></div> <div class="impu-temp5-row"> <div class="impu-temp5-row-left"> <div class="impu-form-line-fr impu-form-links"> <div class="impu-form-links-reg"><a href="https://premiumleakshub.com/vip-register">Register</a> </div> <div class="impu-form-links-pass"><a href="https://premiumleakshub.com/reset-password">Lost your password?</a> </div> </div> </div> <div class="g-recaptcha-wrapper" class=""> <div class="g-recaptcha" data-sitekey="6LfsrjAUAAAAAED3Egwymt-OdRs9OaA72inGD5rV"></div> <script data-cfasync="false" src="/cdn-cgi/scripts/5c5dd728/cloudflare-static/email-decode.min.js"></script> <script type="text/javascript" src="https://www.google.com/recaptcha/api.js?hl=en"></script> </div> <div class="impu-form-line-fr impu-form-submit"><input type="submit" value="Log In" name="Submit" /> </div><div class="iump-clear"> </div> </div> </form> </div> </div> </div> </div> </div> </div>Just nothing but broken HTML…
Thanks for the article on this! I am so sick of seeing all these fake websites with content lockers.
I haven't found one yet that actually HAS any content in the locker if you were lucky enough to bypass it or do the survey.
I don't have any problem at all with clicking an ad to download something. After all, a person's time spent posting stuff should be rewarded. But I just can't stand the deceptive empty content lockers..
That, and the people who post a link that is a monitized ad link, and THAT link goes to another one and another one. And eventually, you get to the actual link to download it.. Greedy much? lol
When I find fake content websites and/or downloaded loaded with malware (and not the false positive type) I will usually go out my way to WHOIS them and find the abuse email contact and file a complaint.
It usually doesn't do much, but it's the best I think we can do short of tracking them down in person and beating them senseless. In that case, being an ex-con I'm defintely down for that! lol
Hey can you help me unlock this site.
I tried doing it but couldn't find the "display:none " that could unlock the link.
https://www.freecourseminer.com/2020/02/01/brian-dean-grow-your-blog-fast/
Yep, because it is not a kind of social content lockers. Users have to authenticate on the web site to get content. The same like you have to login your email box to see its content – it is not social content locker and you cannot get hidden content how it is described about.
https :// shehrozpc . com/easeus-data-recovery-crack/?unapproved=5557&moderation-hash=06e689d6259d1cb6e36d1603d56b6e72#comment-5557 very very please unlocking this link
Hello! The web site link you posted uses CMS WordPress. Sociallocker is one of the plugin for WordPress. At the moment I visited the web site, the Sociallocker plugin is disabled or misused. So we can see only tags:
Bottom line: nothing to extract, either the hidden by Sociallocker content is absent, or the hidden content is just published next to the [sociallocker id=”76″] [/sociallocker] tags.
This is how Sociallocker looks like while it is used properly:
Hello. Thank you for such an accurate answer! Your site is really favorable! For me sociallocking sites is really problematic, because I don't know programming at all, and I really don't have any account in any social network
was the dictatorship introduced on this site that I didn't get any response??
Hello thanks for the article, I am creating a website with a paid subscription simply if the user has not paid re-redirects to another place.
Is it possible with curl to block that redirect? And that a user obtain the html of the page without having paid for the course?
IF this is how you do it to cope with this
Hello, if paid content is present in source code of web pages, it is no chance to protect it. You should use common scheme: authorized users get access to the content according to their subscription plan.
Hey I need your help to open this kind of social lock
_https://www.yasir252.com/software/download-adobe-photoshop-cc-2020-full-version-windows/
Seems like it's using social locker next premium
Hello! Nice challenge! Now my service is able to hack “Social Locker for WordPress / sociallocker-next-premium”.
Absolutely bang up job Alex!
Mind giving some pointer and elaborating on how you did it?
It's not a secret. I have a plan to write a small article about this case. But if you hurry, the next command should help you to understand the main concept:
As well look at the HTML code and find the value of “contentHash” (for example, e408051e78dd01cade57a25100ad70c7).
I see, so unless the "action" has not been performed yet the actual source code won't even serve the part hidden by the locker. But we can request the content by directly referencing the lockerId and hash to the WP..
Really clever.
Thank you for taking a crack at it Alex, God bless.
https://poipiku.com/306507/2449233.html
Can you get me the images hidden on this site it says you have to be mutual following each other on twitter to unlock the content
I'm also looking for an answer to this, is it any way?
would u mind take a look at this? can't seem to unlock this myself this one's harder than i thought https ://www.[CRAPPY].io/musichighcourt/post/hex-cougar-agatha
This bullshit does not work even if ‘connect with facebook’ properly. Don’t waste your time.
i love the article, but i need to print this 1st. there's problem reading in screen for me.
thanks so much.