Comprehensive Guide to John the Ripper. Part 5: Rule-based attack
Table of contents
1. Introducing and Installing John the Ripper
2. Utilities for extracting hashes
4. Practical examples of John the Ripper usage
5.1 What is John the Ripper Rule-Based Attack
5.2 Examples of Rule-Based Attacks in John the Ripper
5.3 John the Ripper Hashcat Compatible Rules
5.7 Charset conversion commands
5.10 Character class and similar commands
5.12 Numeric constants and variables
5.14 Arbitrary characters commands
5.16 Practical examples of John's rule-based attack
5.16.1 Adding arbitrary characters to arbitrary places
5.16.3 Selection of passwords that comply with a certain policy
5.16.4 The button on the user's keyboard is broken
5.16.5 User replaces characters
6. How to brute force non-standard hashes
7, Johnny – GUI for John the Ripper
8.
9.
What is John the Ripper Rule-Based Attack
A rule-based attack is a high-level modification of dictionaries, when they are created and modified not only by adding new symbols, but also with operations inaccessible with masks, such as:
- changing the case of all or individual letters both in the indicated positions and in any places
- switch the whole word to upper or lower case
- switch case to the opposite
- doubling and any number of repetitions of a word
- reverse word order
- word truncation
- deleting a specific range of characters
- replacement of certain characters
- repeat, delete, or overwrite any characters
- removal of words that do not meet the specified criteria (presence or absence of characters or character sets; repeating a character or character set a certain number of times, insufficient or excessive length, etc.)
That is, the rules allow you to change, create new passwords, and also reject password candidates according to certain numerous criteria.
It's a powerful (and fundamentally not that complicated) engine that you might find useful in some unusual situations.
Examples of Rule-Based Attacks in John the Ripper
There is also a rule-based attack in Hashcat (an article will be written on this topic!). If you have already mastered Hashcat rule-based attack, then you need to create files with rules there and specify them using options. John the Ripper also has the --rules option and instinctively you can try to substitute a file with rules in there, but it won't work. All rules must be specified in the configuration file. A long article on John's configuration and remaining options is on its way, for now I'll just point out that the Linux configuration file is named john.conf. If you installed John the Ripper from source, then this file is located in the same folder as the john executable. If you installed from the standard repository of your distribution, then this file is located in the /etc/john/john.conf folder and is also duplicated in /usr/share/john/john.conf. The file can also be in the current working directory or in all places at once. The files do not complement each other – the last loaded file overwrites the previous ones. On Windows, the file is named john.ini.
To understand that these rules are not fearful, let's start with a quick demo.
So, if you run Linux, then open the file /usr/share/john/john.conf:
sudo gedit /usr/share/john/john.conf
Towards the end of the file add the following lines there:
[List.Rules:Toggle] T0 T1 T2 T0T1 T1T2 T0T2 T0T1T2 [List.Rules:Double] d p5 [List.Rules:Reflect] f [List.Rules:Reverse] r
In these lines we have established four sets of rules, they are called Toggle (changes the case of one of the first three letters, then two of the first three letters, and then all three first letters), Double (doubles a word, and also writes a word 5 times in a row), Reflect (reflects the contents of the word and adds to the existing one), Reverse (rewrites the word backwards). We will analyze the meaning of all letters and numbers, but you might already have guessed what they mean in the rules above. The names of the rules are taken arbitrarily, you can choose any.
Save the config file.
Create a passwords.txt file with passwords for tests, example of my file:
craig666 Craig688
Now john needs to be started with options:
- --rules – followed by the name of the set of applied rules
- --wordlist – path to dictionary
- --stdout – just means to output generated passwords to standard output
We run the first command:
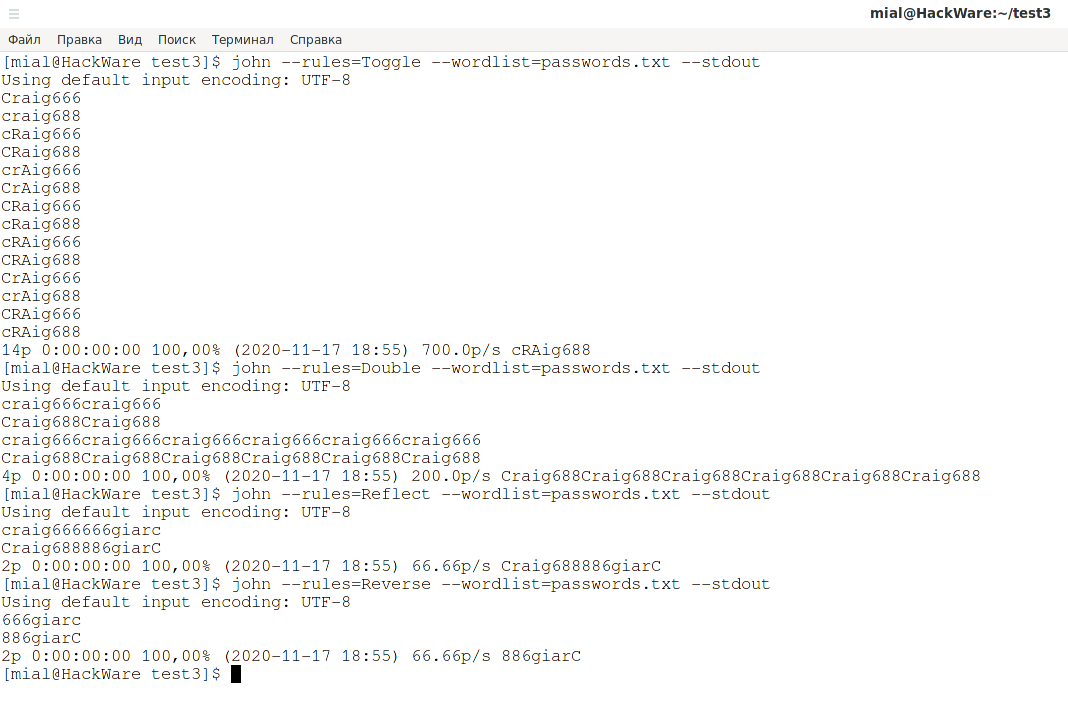
john --rules=Toggle --wordlist=passwords.txt --stdout
We get:
Craig666 craig688 cRaig666 CRaig688 crAig666 CrAig688 CRaig666 cRaig688 cRAig666 CRAig688 CrAig666 crAig688 CRAig666 cRAig688
Trying the second set of rules:
john --rules=Double --wordlist=passwords.txt --stdout
We get:
craig666craig666 Craig688Craig688 craig666craig666craig666craig666craig666craig666 Craig688Craig688Craig688Craig688Craig688Craig688
Third set:
john --rules=Reflect --wordlist=passwords.txt --stdout
Output:
craig666666giarc Craig688886giarC
The last one in which the words are written backwards:
john --rules=Reverse --wordlist=passwords.txt --stdout
We get:
666giarc 886giarC
A group of rules can be collected in one line, or distributed over several lines.
Each line can contain either one rule or many. Many rules are written in a row and are not separated by any signs, or they can be separated by spaces, both entries (with and without spaces) are equivalent.
Single line rules are applied to words at the same time. That is, if you need to make several sequential transformations at once and get one result from one word, then write the rules into a single string.
If you need to make several transformations and save the result of each of them, then write down the rules on separate lines.
For instance,
T0 T1 T2
These are three rules, they change the case in the first, second and third characters of the word and then keep all three new words. That is, three more modifications are obtained from one word, and each of them is preserved.
And the rule
T0T1T2
in the same way changes the case in the first, second and third characters of the word, but keeps only one resulting word.
You can combine strings with one rule and strings with multiple rules.
In these examples, the --stdout option was used for clarity only, in a real crack this option is not needed. Or you can use it to generate dictionaries according to the specified rules.
You can specify any number of rulesets in the configuration file and use them at any time or not at all.
An example of using the rules: make a dictionary match a known password policy; or make all passwords start with a capital letter and other letters in uppercase.
As you can see, nothing fancy. Now let's look at the meanings of all the rules (functions).
John the Ripper Hashcat Compatible Rules
The following features are 100% Hashcat compatible (excluding WN).
| Name | Function | Description | Example Rule | Input Word | Output Word |
|---|---|---|---|---|---|
| Nothing | : | Do nothing (passthrough) | : | p@ssW0rd | p@ssW0rd |
| Lowercase | l | Lowercase all letters | l | p@ssW0rd | p@ssw0rd |
| Uppercase | u | Uppercase all letters | u | p@ssW0rd | P@SSW0RD |
| Capitalize | c | Capitalize the first letter and lower the rest | c | p@ssW0rd | P@ssw0rd |
| Invert Capitalize | C | Lowercase first found character, uppercase the rest | C | p@ssW0rd | p@SSW0RD |
| Toggle Case | t | Toggle the case of all characters in word. | t | p@ssW0rd | P@SSw0RD |
| Toggle @ | TN | Toggle the case of characters at position N | T3 | p@ssW0rd | p@sSW0rd |
| As SHIFT | WN | Toggle character at position N as SHIFT key does | W1 | p@ssW0rd | p2ssW0rd |
| Reverse | r | Reverse the entire word | r | p@ssW0rd | dr0Wss@p |
| Duplicate | d | Duplicate entire word | d | p@ssW0rd | p@ssW0rdp@ssW0rd |
| Duplicate N | pN | Append duplicated word N times | p2 | p@ssW0rd | p@ssW0rdp@ssW0rdp@ssW0rd |
| Reflect | f | Duplicate word reversed | f | p@ssW0rd | p@ssW0rddr0Wss@p |
| Rotate Left | { | Rotate the word left. | { | p@ssW0rd | @ssW0rdp |
| Rotate Right | } | Rotate the word right | } | p@ssW0rd | dp@ssW0r |
| Append Character | $X | Append character X to end | $1 | p@ssW0rd | p@ssW0rd1 |
| Prepend Character | ^X | Prepend character X to front | ^1 | p@ssW0rd | 1p@ssW0rd |
| Truncate left | [ | Delete first character | [ | p@ssW0rd | @ssW0rd |
| Trucate right | ] | Delete last character | ] | p@ssW0rd | p@assW0r |
| Delete @ N | DN | Delete character at position N | D3 | p@ssW0rd | p@sW0rd |
| Extract range | xNM | Extract M characters, starting at position N | x04 | p@ssW0rd | p@ss |
| Omit range | ONM | Delete M characters, starting at position N | O12 | p@ssW0rd | psW0rd |
| Insert @ N | iNX | Insert character X at position N | i4! | p@ssW0rd | p@ss!W0rd |
| Overwrite @ N | oNX | Overwrite character at position N with X | o3$ | p@ssW0rd | p@s$W0rd |
| Truncate @ N | 'N | Truncate word at position N | '6 | p@ssW0rd | p@ssW0 |
| Replace | sXY | Replace all instances of X with Y | ss$ | p@ssW0rd | p@$$W0rd |
| Purge | @X | Purge all instances of X | @s | p@ssW0rd | p@W0rd |
| Duplicate first N | zN | Duplicate first character N times | z2 | p@ssW0rd | ppp@ssW0rd |
| Duplicate last N | ZN | Duplicate last character N times | Z2 | p@ssW0rd | p@ssW0rddd |
| Duplicate all | q | Duplicate every character | q | p@ssW0rd | pp@@ssssWW00rrdd |
| Extract memory | XNMI | Insert substring of length M starting from position N of word saved to memory at position I | lMX428 | p@ssW0rd | p@ssw0rdw0 |
| Append memory | 4 | Append the word saved to memory to current word | uMl4 | p@ssW0rd | p@ssw0rdP@SSW0RD |
| Prepend memory | 6 | Prepend the word saved to memory to current word | rMr6 | p@ssW0rd | dr0Wss@pp@ssW0rd |
| Memorize | M | Memorize current word | lMuX084 | p@ssW0rd | P@SSp@ssw0rdW0RD |
WN is a superset of TN. Whereas TN only switches the case of letters of the alphabet, for example. "A" ↔ "A", the WN command will also toggle with Shift. This is similar to using Shift (or disabling it) on a US keyboard, for example. "1" ↔ "!".
They all support encoding. For example, if the rules engine is running CP737, it will also correctly recognize Greek letters and upper/lowercase letters.
Rule reject flags
| Function | Description |
|---|---|
| -: | no-op: don't reject |
| -c | reject this rule unless current hash type is case-sensitive |
| -8 | reject this rule unless current hash type uses 8-bit characters |
| -s | reject this rule unless some password hashes were split at loading |
| -p | reject this rule unless word pair commands are currently allowed |
| -u | reject this rule unless the rules engine is running in UTF-8 mode (with no internal codepage configured - see doc/ENCODINGS) |
| -U | reject this rule if the rules engine is running in UTF-8 mod |
| ->N | reject this rule unless length N or longer is supported |
| -<N | reject this rule unless length N or shorter is supported (--min-length) |
Length control commands
| Function | Description |
|---|---|
| <N | reject the word unless it is less than N characters long |
| >N | reject the word unless it is greater than N characters long |
| _N | reject the word unless it is N characters long |
| 'N | truncate the word at length N |
| aN | reject the word unless it will pass min/max lengths after adding N characters. Used for early rejection |
| bN | reject the word unless it will pass min/max lengths after removing N characters |
English grammar commands
| Function | Description |
|---|---|
| p | pluralize: "crack" -> "cracks", etc. (lowercase only) |
| P | "crack" -> "cracked", etc. (lowercase only) |
| I | "crack" -> "cracking", etc. (lowercase only) |
Charset conversion commands
| Function | Description |
|---|---|
| S | shift case: "Crack96" -> "cRACK(^" |
| V | lowercase vowels, uppercase consonants: "Crack96" -> "CRaCK96" |
| R | shift each character right, by keyboard: "Crack96" -> "Vtsvl07" |
| L | shift each character left, by keyboard: "Crack96" -> "Xeaxj85" |
NOTE, of these, only S and V are encoding-aware.
Memory access commands
| Function | Description |
|---|---|
| M | memorize the word (for use with "Q", "X", or to update "m") |
| Q | query the memory and reject the word unless it has changed |
| XNMI | extract substring NM from memory and insert into current word at I |
If "Q" or "X" are used without a preceding "M", they read from the initial "word". In other words, you may assume an implied "M" at the start of each rule, and there's no need to ever start a rule with "M" (that "M" would be a no-op). The only reasonable use for "M" is in the middle of a rule, after some commands have possibly modified the word.
The intended use for the "Q" command is to help avoid duplicate candidate passwords that could result from multiple similar rules. For example, if you have the rule "l" (lowercase) somewhere in your ruleset and you want to add the rule "lr" (lowercase and reverse), you could instead write the latter as "lMrQ" in order to avoid producing duplicate candidate passwords for palindromes.
The "X" command extracts a substring from memory (or from the initial word if "M" was never used) starting at position N (in the memorized or initial word) and going for up to M characters. It inserts the substring into the current word at position I. The target position may be "z" for appending the substring, "0" for prefixing the word with it, or it may be any other valid numeric constant or variable. Some example uses, assuming that we're at the start of a rule or after an "M", would be "X011" (duplicate the first character), "Xm1z" (duplicate the last character), "dX0zz" (triplicate the word), "<4X011X113X215" (duplicate every character in a short word), ">9x5zX05z" (rotate long words left by 5 characters, same as ">9{{{{{"), ">9vam4Xa50'l" (rotate right by 5 characters, same as ">9}}}}}").
Numeric commands
| Function | Description |
|---|---|
| vVNM | update "l" (length), then subtract M from N and assign to variable V |
"l" is set to the current word's length, and its new value is usable by this same command (if N or/and M is also "l").
V must be one of "a" through "k". N and M may be any valid numeric constants or initialized variables. It is OK to refer to the same variable in the same command more than once, even three times. For example, "va00" and "vaaa" will both set the variable "a" to zero (but the latter will require "a" to have been previously initialized), whereas "vil2" will set the variable "i" to the current word's length minus 2. If "i" is then used as a character position before the word is modified further, it will refer to the second character from the end. It is OK for intermediate variable values to become negative, but such values should not be directly used as positions or lengths. For example, if we follow our "vil2" somewhere later in the same rule with "vj02vjij", we'll set "j" to "i" plus 2, or to the word's length as of the time of processing of the "vil2" command earlier in the rule.
Character class and similar commands
| Function | Description |
|---|---|
| sXY | replace all characters X in the word with Y |
| s?CY | replace all characters of class C in the word with Y |
| @X | purge all characters X from the word |
| @?C | purge all characters of class C from the word |
| !X | reject the word if it contains character X |
| !?C | reject the word if it contains a character in class C |
| /X | reject the word unless it contains character X |
| /?C | reject the word unless it contains a character in class C |
| =NX | reject the word unless character in position N is equal to X |
| =N?C | reject the word unless character in position N is in class C |
| (X | reject the word unless its first character is X |
| (?C | reject the word unless its first character is in class C |
| )X | reject the word unless its last character is X |
| )?C | reject the word unless its last character is in class C |
| %NXX | reject the word unless it contains at least N instances of X |
| %N?C | reject the word unless it contains at least N characters of class C |
| U | reject the word unless it is valid UTF-8 (use with -u rule reject) |
| eC | title case, where C is the separation character |
| e?C | title case, with chars from class C as separation characters |
NOTE, see hashcat specific 'E' rule which is generic title case for space only characters. The 'e' rule extended more powerful version.
Note that U will accept plain ASCII. It will only reject words that contain 8-bit characters but can't be parsed as UTF-8. It can be used to reject invalid input words, or to reject invalid output words after applying other commands.
Character classes
| Function | Description |
|---|---|
| ?? | matches "?" |
| ?v | matches vowels: "aeiouAEIOU" |
| ?c | matches consonants: "bcdfghjklmnpqrstvwxyzBCDFGHJKLMNPQRSTVWXYZ" |
| ?w | matches whitespace: space and horizontal tabulation characters |
| ?p | matches punctuation: ".,:;'?!`" and the double quote character |
| ?s | matches symbols "$%^&*()-_+=|\<>[]{}#@/~" |
| ?l | matches lowercase letters [a-z] |
| ?u | matches uppercase letters [A-Z] |
| ?d | matches digits [0-9] |
| ?a | matches letters [a-zA-Z] |
| ?x | matches letters and digits [a-zA-Z0-9] |
| ?o | matches control characters |
| ?y | matches valid characters |
| ?z | matches all characters |
| ?b | matches characters with 8th bit set (mnemonic "b for binary") |
| ?N | where N is 0…9 are user-defined character classes. They match characters as defined in john.conf, section [UserClasses] |
The complement of a class can be specified by uppercasing its name. For example, "?D" matches everything but digits.
If you've made John encoding-aware (see doc/ENCODINGS), the applicable national characters are added to the respective classes. So in ISO-8859-1 mode, ?l would include àáâãäåæçèéêëìíîïðñòóôõöøùúûüýþßÿ while in ASCII mode it is only a-z.
Numeric constants and variables
Numeric constants may be specified and variables referred to with the following characters:
| Function | Description |
|---|---|
| 0…9 | for 0…9 |
| A…Z | for 10…35 |
| # | for min_length |
| @ | for (min_length - 1) |
| $ | for (min_length + 1) |
| * | for max_length |
| - | for (max_length - 1) |
| + | for (max_length + 1) |
| a…k | user-defined numeric variables (with the "v" command) |
| l | initial or updated word's length (updated whenever "v" is used) |
| m | initial or memorized word's last character position |
| p | position of the character last found with the "/" or "%" commands |
| z | "infinite" position or length (beyond end of word) |
Here min/max_length is the minimum/maximum plaintext length supported for the current hash type (possibly overridden by --min/max-len options).
These may be used to specify character positions, substring lengths, and other numeric parameters to rule commands as appropriate for a given command. Character positions are numbered starting with 0. Thus, for example, the initial value of "m" (last character position) is one less than that of "l" (length).
String commands
| Function | Description |
|---|---|
| AN"STR" | insert string STR into the word at position N |
To append a string, specify "z" for the position. To prefix the word with a string, specify "0" for the position.
Although the use of the double-quote character is good for readability, you may use any other character not found in STR instead. This is particularly useful when STR contains the double-quote character. There's no way to escape your quotation character of choice within a string (preventing it from ending the string and the command), but you may achieve the same effect by specifying multiple commands one after another. For example, if you choose to use the forward slash as your quotation character, yet it happens to be found in a string and you don't want to reconsider your choice, you may write "Az/yes/$/Az/no/", which will append the string "yes/no". Of course, it is simpler and more efficient to use, say, "Az,yes/no," for the same effect.
Arbitrary characters commands
Any 8-bit character can be used, inside of a Ax"str", a $c or ^c or within preprocessor $[c…] or ^[c…] settings. The method used within john, is similar to emitting an arbitrary character within the C language. This syntax is \xhh where hh is 2 hex characters. So, Az"\x1b[2J" would append then ansi escape sequence to clear the screen to the end of the current password. Or something like $\x0a would append a new line character to the end of the word. These escaped characters also work properly in all character class commands (listed later).
The rule preprocessor
The preprocessor is used to combine similar rules into one source line. For example, if you need to make John try lowercased words with digits appended, you could write a rule for each digit, 10 rules total. Now imagine appending two-digit numbers - the configuration file would get large and ugly.
With the preprocessor you can do these things easier. Simply write one source line containing the common part of these rules followed by the list of characters you would have put into separate rules, in square brackets (the way you would do in a regexp). The preprocessor will then generate the rules for you (at John startup for syntax checking, and once again while cracking, but never keeping all of the expanded rules in memory). For the examples above, the source lines will be "l$[0-9]" (lowercase and append a digit) and "l$[0-9]$[0-9]" (lowercase and append two digits). These source lines will be expanded to 10 and 100 rules, respectively. By the way, preprocessor commands are processed right-to-left while character lists are processed left-to-right, which results in natural ordering of numbers in the above examples and in other typical cases. Note that arbitrary combinations of character ranges and character lists are valid. For example, "[aeiou]" will use vowels, whereas "[aeiou0-9]" will use vowels and digits. If you need to have John try vowels followed by all other letters, you can use "[aeioua-z]" - the preprocessor is smart enough not to produce duplicate rules in such cases (although this behavior may be disabled with the "\r" magic escape sequence described below).
There are some special characters in rules ("[" starts a preprocessor character list, "-" marks a range inside the list, etc.) You should prefix them with a backslash ("\") if you want to put them inside a rule without using their special meaning. Of course, the same applies to "\" itself. Also, if you need to start a preprocessor character list at the very beginning of a line, you'll have to prefix it with a ":" (the no-op rule command), or it would be treated as a new section start.
Finally, the preprocessor supports some magic escape sequences. These start with a backslash and use characters that you would not normally need to escape. In the following paragraph describing the escapes, the word "range" refers to a single instance of a mix of character lists and/or ranges placed in square brackets as illustrated above.
Currently supported are "\1" through "\9" for back-references to prior ranges (these will be substituted by the same character that is currently substituted for the referenced range, with ranges numbered from 1, left-to-right), "\0" for back-reference to the immediately preceding range, "\p" before a range to have that range processed "in parallel" with all preceding ranges, "\p1" through "\p9" to have the range processed "in parallel" with the specific referenced range, "\p0" to have the range processed "in parallel" with the immediately preceding range, and "\r" to allow the range to produce repeated characters. The "\r" escape is only useful if the range is "parallel" to another one or if there's at least one other range "parallel" to this one, because you should not want to actually produce duplicate rules. Also the \xhh escape works properly within the preprocessor, to allow any character. The preprocess rule [\x01-\xff] will be replaced with 255 characters (missing the NULL byte, which can not be handled by JtR).
Practical examples of John's rule-based attack
1. Adding arbitrary characters to arbitrary places
Suppose the user encrypted files with the same password, let's say it is "long_password", but at some point decided to complicate the password and added several characters (from 1 to 3) to it. The user remembers that these are some lowercase letters, but he does not remember which ones and in what places of the password he added them.
Task: to compose rules for password modification based on the specified conditions.
Let's use the "iNX" function, which inserts the X at position N.
A rule that adds small letters ([a-z]) at positions 0 through 13:
i[0-9A-D][a-z]
Position 13 was selected last, since there are only 13 letters in long_password. The zero position is before the word, the thirteenth position is after the password.
Unlike Hashcat, John the Ripper supports ranges, so the characters to be inserted are specified as range — [a-z].
The positions to insert characters are also specified as a range — [0-9A-D]. In it, "0-9" means to insert in position from 0 to 9. And "A-D" means to insert in position from 10th to 13th.
The previous rule only inserts one letter. To insert any two small letters anywhere in a word, use the following rule:
i[0-9A-D][a-z] i[0-9A-D][a-z]
It is obtained from the previous one by simply doubling the record.
The following rule will insert any three lowercase letters anywhere in the word:
i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z]
So, add to the file /usr/share/john/john.conf
sudo gedit /usr/share/john/john.conf
the following lines with our rules:
[List.Rules:Add3SmallLet] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z]
Let's save the original password "long_password" to the passwords.txt file.
The written ruleset is named Add3SmallLet, our original password is placed in the passwords.txt file, then the command to view the generated passwords based on the rules is as follows:
john --rules=Add3SmallLet --wordlist=passwords.txt --stdout
Please note that these rules will create, among other things, duplicate passwords, if you want to create a dictionary, then filter out duplicates with a command of the following type:
john --rules=Add3SmallLet --wordlist=passwords.txt --stdout | sort | uniq
2. Adding arbitrary characters to arbitrary places and replacing characters in the password with arbitrary characters
Suppose a user encrypted files with the same password, let's say it's "long_password", but at some point decided to complicate the password and added several characters (from 1 to 3) to it, and also decided to replace some characters with numbers. The user remembers that he added some lowercase letters, but he does not remember which ones and where in the password he added them. Also, the user remembers that he replaced no more than two characters with numbers in the password, it is possible that not a single character.
Task: to compose rules for password modification based on the specified conditions.
Let's use the already discussed function "iNX", which inserts the character X at position N.
We will also use the "oNX" function, which rewrites the character at position N to X.
To fulfill the first part of the condition (adding 1-3 small letters in arbitrary places), we will use the rules compiled in the previous part.
i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z]
The rule to replace one character at positions 0 through 13 with any digit is as follows:
o[0-9A-D][0-9]
To replace two digits, that is, to apply one rule twice, write down the resulting rule twice:
o[0-9A-D][0-9] o[0-9A-D][0-9]
According to the terms of the problem, the replacement of symbols is accompanied by the addition of symbols or is absent at all.
Then the set of rules for writing to the /usr/share/john/john.conf file is as follows:
[List.Rules:AddAndReplace] i[0-9A-D][a-z] # add one letter i[0-9A-D][a-z] i[0-9A-D][a-z] # add two letters i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] # add three letters i[0-9A-D][a-z] o[0-9A-D][0-9] # add one letter and replace one character with a digit i[0-9A-D][a-z] i[0-9A-D][a-z] o[0-9A-D][0-9] # add two letters and replace one character with a digit i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] o[0-9A-D][0-9] # add three letters and replacing one character with a digit i[0-9A-D][a-z] o[0-9A-D][0-9] o[0-9A-D][0-9] # add one letter and replace two characters with numbers i[0-9A-D][a-z] i[0-9A-D][a-z] o[0-9A-D][0-9] o[0-9A-D][0-9] # add two letters and replacing two characters with numbers i[0-9A-D][a-z] i[0-9A-D][a-z] i[0-9A-D][a-z] o[0-9A-D][0-9] o[0-9A-D][0-9] # add three letters and replace two characters with numbers
Let's save the original password "long_password" to the passwords.txt file.
The written ruleset is named AddAndReplace, our original password is placed in the passwords.txt file, then the command to view the generated passwords based on the rules is as follows:
john --rules=AddAndReplace --wordlist=passwords.txt --stdout
Please note that these rules will create, among other things, duplicate passwords, if you want to create a dictionary, then filter out duplicates with a command of the following type:
john --rules=AddAndReplace --wordlist=passwords.txt --stdout | sort | uniq
3. Selection of passwords that comply with a certain policy
It is known that the organization has the following password policy: the password must contain at least one capital letter; at least one lowercase letter; at least one digit and at least one special character. Password length cannot be less than 8 characters.
The task is to prepare a dictionary for hash cracking, which takes into account the policy of password requirements and removes passwords that do not match the criteria.
For this we need two rules:
- /?C — means to reject a word if it does not contain a character in class C.
- >N — means to reject the word if it does not exceed N characters
Let's turn to the table "Character classes".
This rule set rejects passwords that do not contain at least one of the characters: lowercase letter, uppercase letter, number, punctuation marks:
/?l /?u /?d /?p
Since passwords may contain other special characters, another set of rules needs to be compiled:
/?l /?u /?d /?s
This second set of rules rejects passwords that do not contain at least one of the characters: lowercase letter, uppercase letter, number, special character.
Within one line, there is a logical "AND" applied, that is, all passwords that are missing at least one character class will be discarded.
But there is a logical "OR" between the lines, that is, all passwords that meet the criteria of the first line or the criteria of the second line will be skipped.
/?l /?u /?d /?p >7 /?l /?u /?d /?s >7
Add the following lines to the /usr/share/john/john.conf file (the ruleset is named StrongPass):
[List.Rules:StrongPass] /?l /?u /?d /?p >7 /?l /?u /?d /?s >7
To check their performance, download the dictionary:
wget -U 'Chrome' https://kali.tools/files/passwords/leaked_passwords/rockyou.txt.bz2 7z e rockyou.txt.bz2
Let's check the number of passwords in it:
cat rockyou.txt | wc -l 14344391
That is, there are 14.344.391 (fourteen million) passwords in the file.
Now let's check how many passwords will be filtered:
john --rules=StrongPass --wordlist=rockyou.txt --stdout | wc -l
Output:
Using default input encoding: UTF-8 Press 'q' or Ctrl-C to abort, almost any other key for status 50785p 0:00:00:01 100,00% (2020-11-29 17:08) 35764p/s *7¡Vamos! 50785
There are only 50,785 password candidates left that match the specified conditions! This is 50785 ÷ 14344391 × 100 = 0.35% of the entire dictionary!!! That is, if we had not used this optimization, 99.65% of calculations during brute-force would be meaningless, since we would be checking knowingly inappropriate passwords.
4. The button on the user's keyboard is broken
It is known that from frequent playing on the computer the buttons "a", "s", "d", "w" are broken. For this reason, the user never uses these letters when entering passwords.
Objectives: filter out from the dictionary all candidates for passwords that contain these letters. In this case, it should be assumed that the user can enter words by omitting these letters.
To fulfill this condition, we need two rules:
- !X — means to reject the word if it contains the character X
- @X — means to remove all X characters from a word
A set of rules that rejects all words if they contain any of the specified characters:
!a !s !d !w !A !S !D !W
A set of rules that allows all words but removes the specified characters from them:
@a @s @d @w @A @S @D @W
These rules do NOT need to be used together, as they will create many duplicates (the subset of the second rule's password candidates fully includes the subset of the first rule's password candidates).
The first rule should be applied if the owner of the faulty keyboard is not used by words with the specified characters. The second rule is useful if the owner of the faulty keyboard still uses words with the specified characters, but skips these characters during input.
5. User replaces characters
It is known that when entering words, the user always replaces the character I with 1, O with 0, and the character S with $.
Objective: to change the dictionary so that the specified characters are replaced in it.
To solve this problem, we need one rule:
- sXY — means replace all X characters in a word with Y
A set of rules that replaces the three specified characters:
sI1 sO0 sS$
Add the following lines to the /usr/share/john/john.conf file (the set of rules is named Replace):
[List.Rules:Replace] sI1 sO0 sS$
Now we can make sure that all new words are missing the letters I, O and S (replaced by 1, 0 and $):
john --rules=Replace --wordlist=rockyou.txt --stdout | grep -E 'I|O|S'
The output will be empty because no word with I, O and S will be found.
Important to remember
Rules that create new words (by changing the case of letters, adding characters) usually tend to generate duplicates, especially if several rules of the same type are used. If you are creating a dictionary, then use the construction “john OUTPUT | sort | uniq > DICTIONARY.txt".
Related articles:
- Advanced wordlist generating techniques (97.5%)
- How to create dictionaries that comply with specific password strength policies (using Rule-based attack) (83.4%)
- Comprehensive Guide to John the Ripper. Part 6: How to brute force non-standard hashes (80.5%)
- Comprehensive Guide to John the Ripper. Part 7: Johnny – GUI for John the Ripper (80.5%)
- How to generate dictionaries by any parameters with pydictor (78.7%)
- Active Directory comprehensive guide, from installation and configuration to security auditing. Part 5: Join computers to Active Directory. Check and unjoin from Active Directory (RANDOM - 1%)
Hi.
I need to find a password which has only lowercase letters and numbers. But I don't know which part is number or which part is letter.
I tried incremental mode with LowerNum, but it tries these three combinations:
1-) All the characters as lowercase letters
2-) All the characters as digits
3-) Lowercase letters + digits
I only need the third option. How can I do that with John the Ripper without wordlist creating? I know I can do with mask mode like: --mask=[a-z0-9][a-z0-9][a-z0-9][a-z0-9][a-z0-9][a-z0-9][a-z0-9][a-z0-9] but I want to use incremental mode.
JtR can read passwords from standard input (stdin). This way you can generate and filter passwords that match your criteria and pass them to John's standard input.
To generate and filter passwords and then pass them to john, use a command like:
Thanks, but I need a solution for incremental mode. Because I want to use JtR's built-in keywords to find the password. I think your command is generating all possible passwords for number+lowercase letter like mine on my first message.
Hi. I'm using John to create my wordlist but I have a problem. I have a word:
seesaw
and I need to replace the s symbol with $. I would use ss$ but it returns only $ee$aw when I need:
seesaw
$eesaw
see$aw
$ee$aw
I also need to do that with other characters but once I know how to do this one it wont be a problem. Is there a way to do that?
Hello! I answered your question in this article.
Thank you very much!
Hi Alex,
I appreciate your lessons here but please I am attempting to recover a password, I know the first letter was capitalized, there is just one symbol( . _ or - ) at the middle, three letters of lower case and some missing four lower case letters followed by 123 at the end of the password, 13 in lenght. I have used the rules on hashcat and Onerule but those rules are not using my own wordlist as candidates except only with the first and last word in my wordlist. I need a rule that will use my own wordlist to create the password I am looking for. Please Alex, how can i create such rule that will only create or use words from my own wordlist. I will appreciate your assistance on this subject. I created the wordlist from two combination so i can apply rules to recover the password using the created wordlist. Thank you.
Best Regards
Please Alex, regarding my previous comment: This is it. Z??ber????123. Please I need an assistance in creating a rule for finding such password using my own wordlist as i previously explained. Thank you
Best Regards